![]()
The Future of Data Quality and Data Observability with Agentic AI

Raj Joseph
Founder & CEO, DQLabs
Raj Joseph
Founder & CEO, DQLabs
Ensure Effective Data Quality Management in Redshift Spectrum
Overview
Redshift Spectrum is an extension of Amazon Redshift that enables users to query data stored in Amazon S3 buckets directly from their Redshift cluster. It allows users to use their existing SQL query skills to analyze data stored in S3 without the need to load it into Redshift first. Redshift Spectrum leverages Redshift's massively parallel processing (MPP) architecture to parallelize and distribute queries across Redshift and S3. It supports various data formats, including CSV, JSON, Avro, and Parquet, and can handle petabytes of data stored in S3.
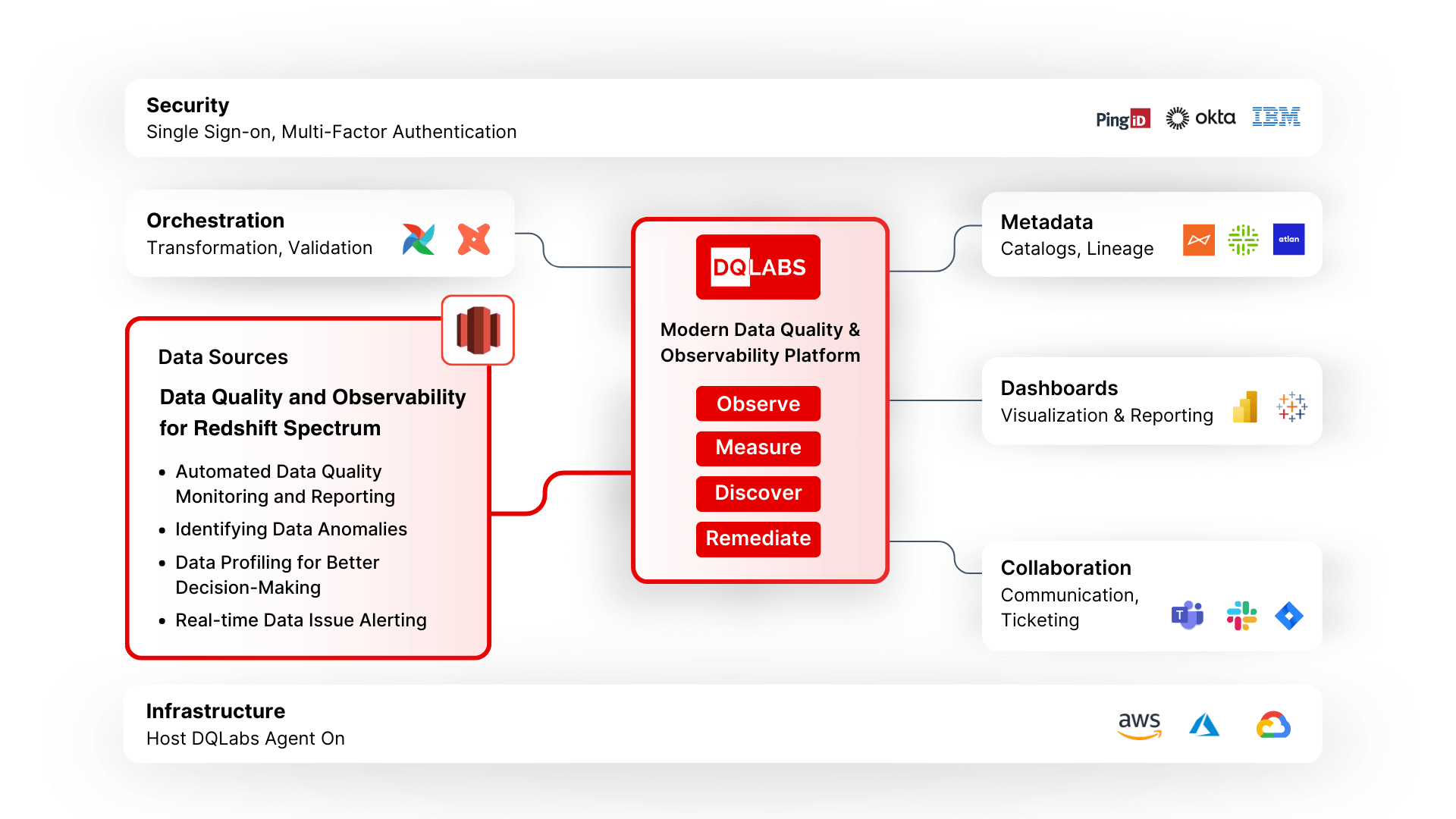
By integrating Amazon Redshift Spectrum with DQLabs, organizations can effortlessly identify, address, and prevent data quality issues. With automated monitoring and anomaly detection, you can proactively ensure data quality throughout your environment, identifying problematic data before it affects downstream processes. Create and manage incidents to swiftly address issues, enabling teams to rely on trustworthy data for all their operations and business initiatives.