
Summarize and analyze this article with
As a data engineer, one of your primary goals is to build, manage, and optimize data pipelines for data movement. The pipelines that you choose to build or buy are the essential carriers of data that your organization’s analysts and scientists rely on for their analyses and decisions.
While pipelines seem straightforward – moving data and combining sources – the growing volume and diversity of data throws a wrench in the works. A simple update in your favorite CRM software can break your data model, causing a “schema drift” that leaves analysts scratching their heads.
This blog is a deep dive into what data pipelines are and how to implement them successfully to help businesses gain a competitive edge. It also discusses types of data pipelines, components of data pipelines, their architecture, use cases, and the latest trends.
What is a Data Pipeline?
A data pipeline is a comprehensive system that facilitates the movement, transformation, and processing of data from one or more sources to a destination, where it can be utilized for analysis, reporting, and decision-making. It encompasses the various steps involved in collecting, cleaning, integrating, and delivering data in a usable format.
At its core, a data pipeline is responsible for extracting data from disparate sources, transforming it into a standardized format, and loading it into a target system, such as a data warehouse or data lake. This process is often referred to as ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform), depending on when the transformation happens.
When and Why Do You Need a Data Pipeline?
In today’s world, characterized by a staggering growth rate in data volume, having more data isn’t simply about accumulating facts and figures. It fundamentally transforms how we manage and utilize it to our advantage. The vast quantity of data from diverse sources presents challenges in management, integration, and analysis. However, data pipelines can help us solve this problem.
Data pipelines serve several critical purposes such as,
- Data consolidation: By bringing together data from various sources, such as databases, SaaS applications, and external data providers, data pipelines create a centralized and unified view of an organization’s data assets.
- Data transformation and enrichment: Data pipelines transform raw data into a format that is suitable for analysis and reporting, often by applying data cleansing, normalization, and enrichment processes.
- Improved data quality: Data pipelines help ensure data quality by implementing data validation, error handling, and anomaly detection mechanisms, reducing the risk of inaccurate or incomplete data that can otherwise impact data consumers.
- Scalability and efficiency: Automated data pipelines can handle large volumes of data and scale up or down as needed, improving the overall efficiency and performance of your data-driven processes.
- Real-time data processing: Streaming data pipelines enable the processing of data in real-time, allowing organizations to make informed decisions in a cost-efficient way.
- Data governance and compliance: Data pipelines can incorporate data governance policies and controls, ensuring that data is managed and used in accordance with regulatory requirements and organizational standards.
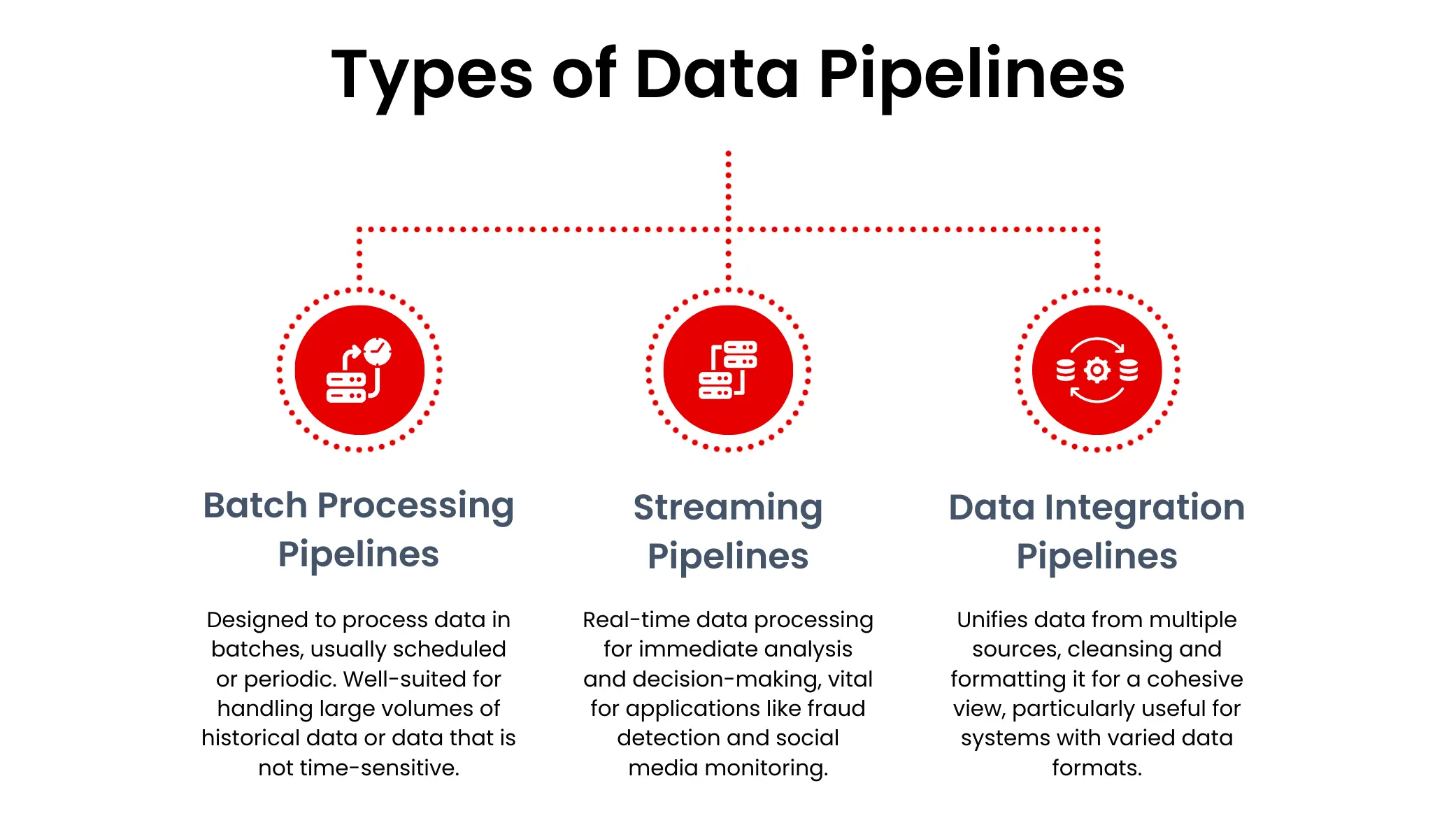
Types of Data Pipelines
Data pipelines can be broadly categorized into three main types:
- Batch processing pipelines: These pipelines are designed to process data in batches, typically on a scheduled or periodic basis. Batch processing is well-suited for handling large volumes of historical data or data that is not time-sensitive.
- Streaming pipelines: Streaming pipelines are used to process data in real-time as it is generated, enabling immediate analysis and decision-making. These pipelines are often used for applications that require rapid response times, such as fraud detection, sensor data analysis, or social media monitoring. Some organizations may also employ a hybrid approach, known as the Lambda architecture, which combines batch and streaming processing to leverage the strengths of both approaches.
- Data integration pipelines: These pipelines bring data together from many sources, creating a single view. They often clean and change the raw data before storing it in a central location. This is useful when different systems use different formats for their data.
Components of a Data Pipeline
The following are the key components of a typical data pipeline:
- Data sources: The origin of the data, which can include databases, SaaS applications, IoT devices, or any other system that generates data.
- Data ingestion: The process of extracting data from the source systems and bringing it into the data pipeline.
- Data transformation: The steps involved in cleaning, normalizing, and enriching the data to prepare it for analysis.
- Data storage: The destination for the processed data, which can be a data warehouse, data lake, or other data repository.
- Data processing: The computational tasks performed on the data, such as aggregation, filtering, or machine learning model training.
- Data orchestration: The coordination and scheduling of the various steps in the data pipeline, ensuring that data flows seamlessly from one stage to the next.
- Data monitoring and observability: The tools and techniques used to track the health, performance, and reliability of the data pipeline.
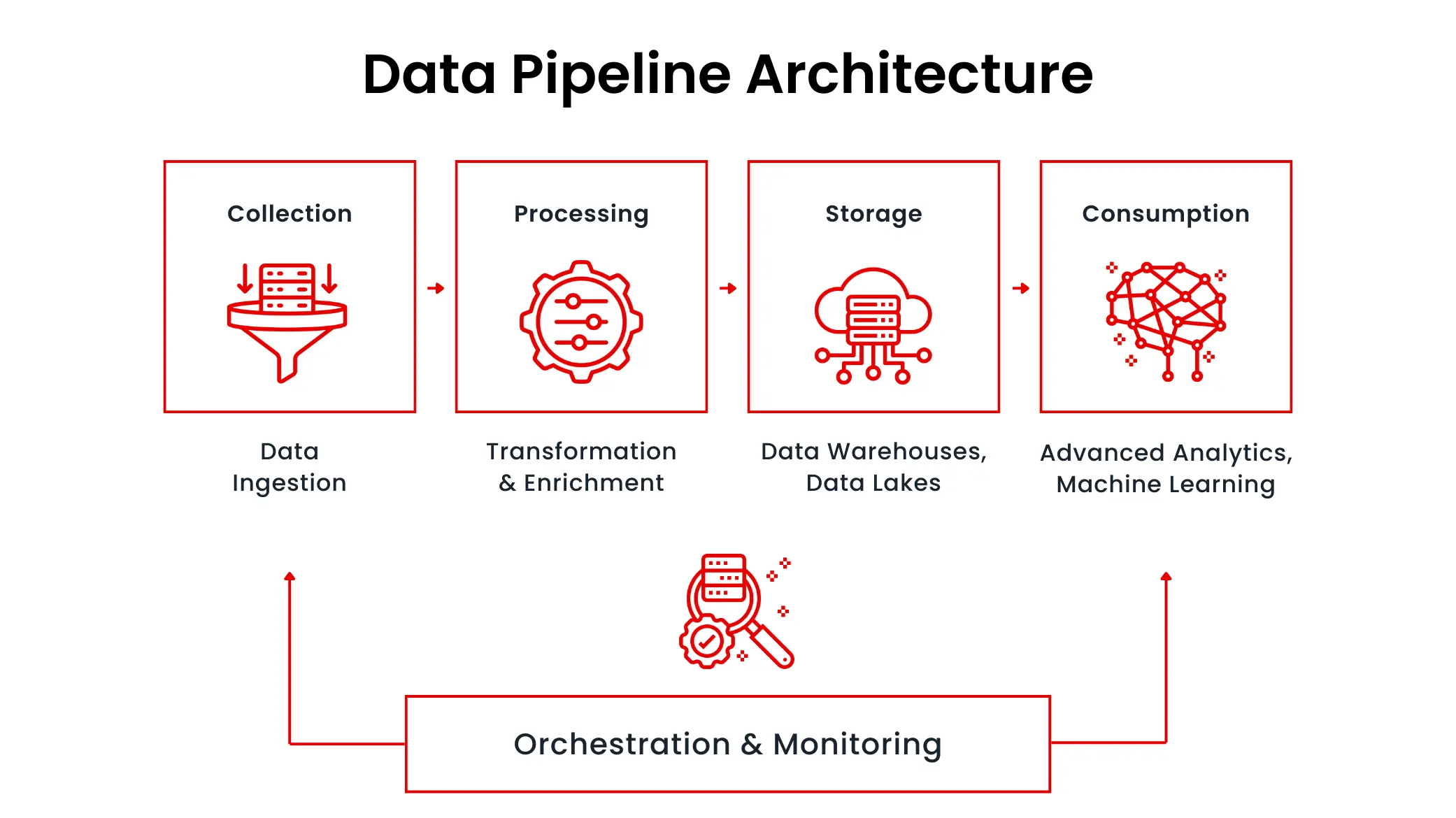
Data Pipeline Architecture
The architecture of a data pipeline can vary depending on the specific requirements of an organization, but it typically follows a common pattern:
- Data ingestion layer: This layer is responsible for extracting data from various sources, often using tools like Apache Kafka, Amazon Kinesis, or Azure Event Hubs for real-time data, and batch-based tools like Apache Sqoop or Fivetran for historical data.
- Data processing layer: This layer handles the transformation, enrichment, and processing of the data, using tools like Apache Spark, Databricks, or AWS Glue to perform ETL or ELT tasks.
- Data storage layer: This layer is where the processed data is stored, often in a data warehouse (e.g., Snowflake, BigQuery, Redshift) or a data lake (e.g., Amazon S3, Azure Data Lake Storage, Google Cloud Storage).
- Data consumption layer: This layer provides access to the processed data for downstream applications, business intelligence tools, and data consumers, enabling data-driven decision-making.
- Orchestration and monitoring layer: This layer coordinates the various components of the data pipeline, schedules and monitors the data processing tasks, and ensures the overall reliability and performance of the system.
Read: You can read more about ETL processes used in data pipelines here.
Best Practices for Implementing Efficient Data Pipelines
Building and maintaining effective data pipelines is no easy feat. It requires careful planning, execution, and ongoing optimization. Here are some best practices to follow when implementing data pipelines:
- Define clear goals and requirements: Start by clearly identifying the purpose of your data pipeline, the frequency of data updates and source systems (databases, APIs, flat files). This knowledge lays the groundwork for designing an efficient ingestion process that meets your specific needs and requirements.
- Choose the right tools and technologies: Select appropriate data storage solutions (e.g., data warehouses, data lakes) and processing tools (e.g., Apache Spark, Apache Flink) based on your requirements. Consider factors such as scalability, performance, and ease of use.
- Design for scalability: Design modular pipelines where components can be easily added, removed, or swapped without impacting the entire system. Using cloud-based solutions can further improve your flexibility. This will be crucial as data sources evolve, whether it’s a new API, schema changes, or the likes.
- Incorporate data quality checks: Integrate data quality checks right at the data entry point. Look for missing values, duplicates, and anomalies that might signify issues. Catching and rectifying errors at this stage saves downstream effort and prevents “garbage in, garbage out” scenarios.
- Maintain data lineage and metadata: Track the origin of data and any transformations it undergoes. Store metadata about data types, source systems, and update frequencies. This information is essential for debugging, compliance, and ensuring data integrity.
- Implement error handling and retries: Handle errors and automatically retry failed tasks to ensure data is processed reliably. This helps maintain data integrity and reduces manual intervention.
- Automate pipeline deployment and testing: Use tools and scripts to automate pipeline deployment and testing to ensure consistency and reduce manual effort. This also enables faster iteration and experimentation.
- Test, monitor and optimize continuously: Just like any software system, data pipelines require regular testing too. You should also monitor pipeline health and performance, and make adjustments to optimize efficiency and reliability. This may involve techniques such as data lineage tracking, impact analysis, and root cause analysis.
- Ensure data security and compliance: Implement appropriate security measures and comply with relevant data regulations to protect sensitive data and avoid legal issues. Safeguard sensitive data both at rest and in transit. Practices like encryption, access controls, regular audits, and data retention policies are crucial.
By following these best practices, data engineers can build efficient, reliable, and scalable data pipelines that deliver high-quality data to downstream consumers for improved decision-making.
Use Cases and Business Applications of Data Pipelines
Data pipelines have a wide range of business applications across various industries. Some key use cases include:
- Ready to analyze data: Data pipelines enable the extraction of raw data from source systems, transformation to meet specific requirements, and loading into data warehouses for analysis. This ensures organized storage of historical data and easy accessibility for future insights.
- Keeps quality intact: Data pipelines seamlessly ingest, clean, and transform data from various sources into data warehouses. This creates centralized hubs for analysts to query massive datasets without impacting operational systems. By automating essential preprocessing tasks like feature extraction and normalization, data pipelines ensure high-quality training data for machine learning models. This frees data scientists to focus on building high-quality models.
- Enables recommendation engine: Companies utilize data pipelines to process user activity logs, product catalog information, and customer profiles for e-commerce recommendation engines. These pipelines feed raw data into machine learning systems to generate personalized product recommendations.
- Detects fraudulent activities: Advanced analytics systems powered by data pipelines help banks detect fraudulent activities in transactional datasets. These pipelines process real-time and historical transaction records, extract relevant features, and train machine learning models to identify potential frauds and investment decision-making.
These examples demonstrate the versatility and significance of data pipelines in modern data management, analytics, and decision support across various industries.
Future Outlook and Trends
The data pipeline landscape is rapidly evolving, driven by advancements in cloud computing, big data technologies, and the increasing demand for real-time data processing and analysis. Some key trends and future developments in the data pipeline space include:
- Serverless and cloud-native architectures: The adoption of serverless computing and cloud-native technologies, such as AWS Glue, Azure Data Factory, and Google Cloud Dataflow, will continue to simplify the deployment and management of data pipelines.
- Increased automation and AI-driven development: The integration of machine learning and artificial intelligence into data pipeline processes will enable greater automation, self-healing capabilities, and intelligent data processing.
- Streaming data and real-time analytics: The growing importance of real-time data processing and analysis will drive the adoption of streaming data pipelines, allowing organizations to make faster, more informed decisions.
- Data governance and compliance: Stricter data regulations and the need for data privacy will lead to the incorporation of robust data governance frameworks within data pipeline architectures.
- Democratization of data pipeline development: The rise of no-code and low-code data quality platforms, like DQLabs, will empower business users to participate in the design and customization of data pipelines, bridging the gap between IT and business teams.
As the volume, variety, and velocity of data continue to grow, the importance of efficient and reliable data pipelines will only increase. By adopting the latest trends and best practices, data engineers can build pipelines that extract maximum value from an organization’s data assets, empowering data-driven decision-making for sustainable business success.
You can also adopt a data observability solution like DQLabs to make these easier for you. DQLabs tracks the health, performance, and reliability of your data pipelines, enabling proactive issue identification and resolution.