Businesses are capturing and storing information at unprecedented rates, with a focus on leveraging these insights for data-driven decision making. However, this data surge coincides with tightening budgets, with 81% of IT leaders facing pressure from executives to limit or reduce cloud storage costs.
For data teams, this translates to a critical challenge: balancing the need for powerful, scalable data storage with strict cost constraints. Choosing the right foundation for your data platform – the storage layer – is paramount.
Further complicating the decision are the evolving options available. Data warehouses, data lakes, and the emerging data lakehouse each offer unique advantages and drawbacks, making the selection process even more nuanced.
This blog dives into the key differences between data lakes and data warehouses, helping you to make an informed decision about the optimal storage solution for your organization’s specific needs.
What is a Data Lake?
A data lake is a centralized repository that allows organizations to store large volumes of raw, structured, semi-structured, and unstructured data in its native format. This includes everything from text and images to videos and social media posts. Data lakes enable cost-effective storage using solutions like cloud-based object storage, making it feasible to store data from diverse sources such as IoT devices, social media platforms, and web analytics without the need for prior data processing or transformation.
Data lakes also support a wide range of use cases, including big data analytics, machine learning, and data science. The inherent flexibility of data lakes allows them to ingest and store petabytes of data, regardless of format – structured, semi-structured, or unstructured – making them ideal for enterprises with diverse data requirements.
However, without proper data management and governance, data lakes can turn into “data swamps” with unusable data. Therefore, it is important to implement data governance standards to maintain data quality and accessibility.
Benefits of Data Lakes
- Diverse Data Handling: Data lakes manage both structured and unstructured data, accommodating everything from financial records to social media feeds and multimedia content.
- Data Accessibility: Data lakes uses flat architecture and object storage with metadata tags and unique identifiers to retrieve data easily.
- Flexibility: Data lakes support a variety of tools and frameworks for real-time analytics, business intelligence, data science, and machine learning. This flexibility helps businesses to adapt their data strategies to new technologies whenever the need arises.
- Cost-Effective: These are more cost-effective than data warehouses. They scale quickly, handle diverse data types, and eliminate the need for costly data transformation processes upfront.
Read more: You can read all about data lakes here!
Uses Cases of Data Lakes
- Advanced Analytics & Machine Learning: Data lakes fuel advanced analytics, enabling businesses to predict future trends, personalize customer experiences, and do real-time sentiment analysis from various sources with low latency. They can hold raw data for a long time at low cost.
- Business Intelligence & Data Science: Beyond structured data, data lakes open doors for data science exploration. This allows for innovative applications in machine learning, advanced statistics, and even real-time data serving for recommender systems or fraud detection.
- Centralized Data Hub: Data lakes act as a central repository, storing massive volumes of data from various departments. This global view allows historical data storage for trend analysis and compliance in an accessible way.
- Real-Time Insights & Reporting: Data lakes enable the creation of interactive dashboards that aggregate data from various sources. This allows for data-driven decision making based on up-to-date insights. This is possible because it is a common landing zone for data that is always up-to-date.
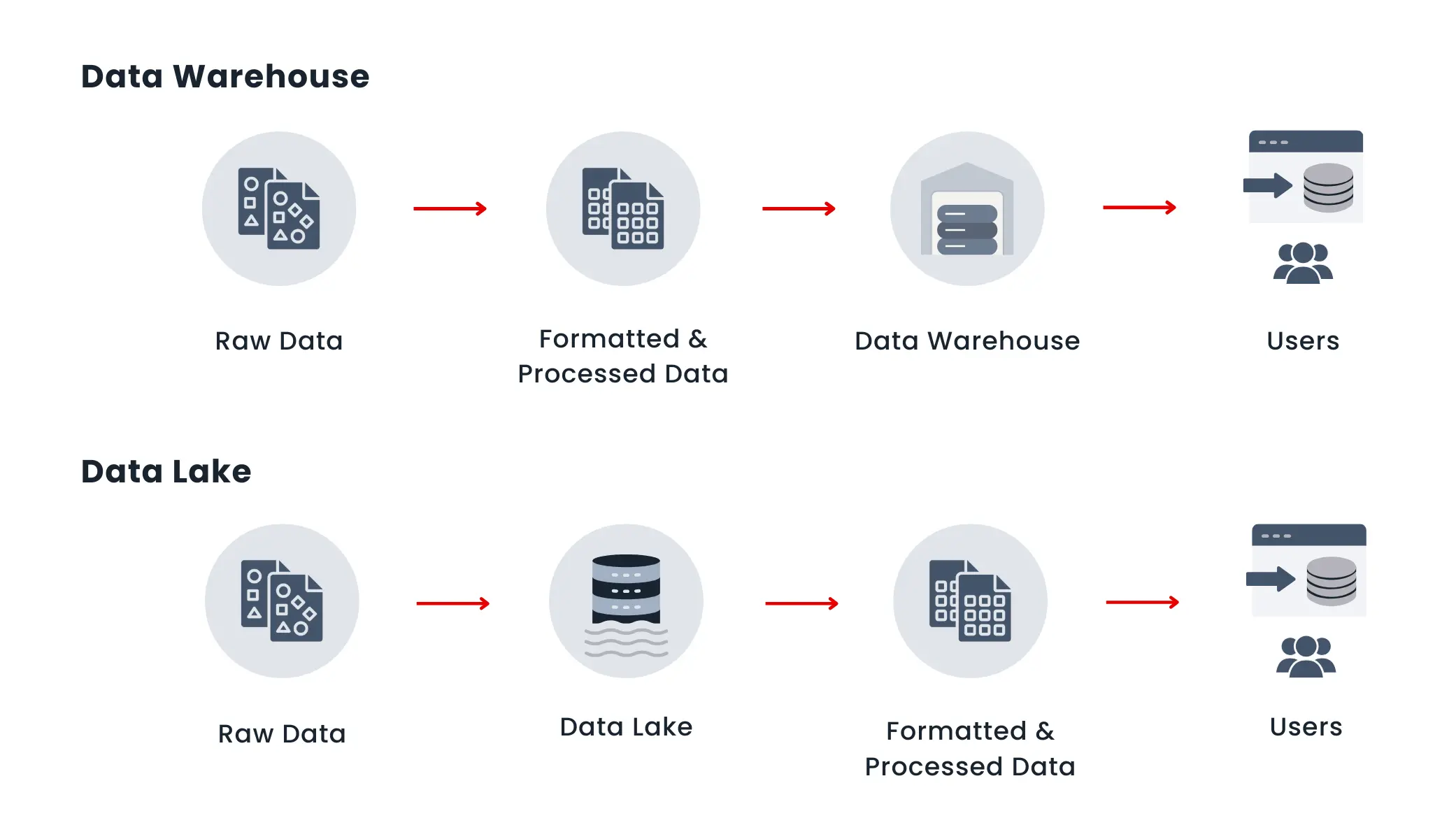
What is a Data Warehouse?
A data warehouse is a centralized repository designed to store structured data for business intelligence activities like analysis, reporting, and decision-making. Data warehouses organize data into tables with predefined schemas, unlike data lakes. This structured approach simplifies data management, ensuring consistent and high-quality data that is easy to query using SQL.
Data warehouses integrate storage, compute, and metadata management, often provided by a single vendor. Leading solutions include Amazon Redshift, Google BigQuery, and Snowflake. These platforms support complex queries and efficient data analysis, making them ideal for data analytics and reporting.
While data warehouses require data transformation through ETL processes, their structured nature allows for seamless sharing of insights across departments. However, this process can be resource-intensive and may not scale well with the growing volume of data. Despite this, data warehouses remain a cornerstone for organizations needing reliable, actionable data insights, particularly in industries like finance, healthcare, and retail where operational histories are important and data warehouses store them that way.
Benefits of Data Warehouses
- Improved Business Intelligence: Data warehouses centralize data from multiple sources, providing a global view for deriving insights. This consolidation aids in creating detailed reports and facilitates collaboration across departments.
- Quick Decision Making: By consolidating data into one repository, data warehouses streamline access to critical information in one place, enabling quick and effective decisions. AI algorithms can further help identify valuable business trends.
- Data Quality Management: Data warehouses simplify data cleansing, ensuring accurate and consistent data by comparing sources and removing inaccuracies. These days most of them also have sanitation techniques to make data cleansing easier.
- Increased Data Security: Centralized storage simplifies data protection with encryption and user access controls, safeguarding sensitive information.
- Higher ROI: Data warehouses improve data quality, accessibility, and operational efficiency, leading to increased revenue and reduced costs because of resource optimization.
Uses Cases of Data Warehouses
- Financial Planning: Consolidate data for budget forecasting, scenario analysis, and profitability insights in compliant format to guide quick strategic planning and investments.
- Marketing Campaigns: Merge CRM, web analytics, and advertising data for efficient campaigns, real-time adjustments, and improve your ROI tracking.
- Legacy Systems Integration: Through the use of ETL, warehouses can transform legacy data format to something that suits newer applications for comprehensive historical insights.
- IoT Data Integration: IoT and other network connected devices require their data to be collected and stored in relational data formats. To discover anomalies and do real-time series analysis, they need a platform that is easy-to-access and flexible enough to account for real time changes quickly.
DQLabs integrates with every part of the modern data stack: from lakes, warehouses, to transformation tools, to BI platforms. Try us for your modern data team.
Key Differences Between a Data Lake and a Data Warehouse
When deciding between a data lake and a data warehouse, understanding the differences can help determine which solution best meets your organization’s needs.
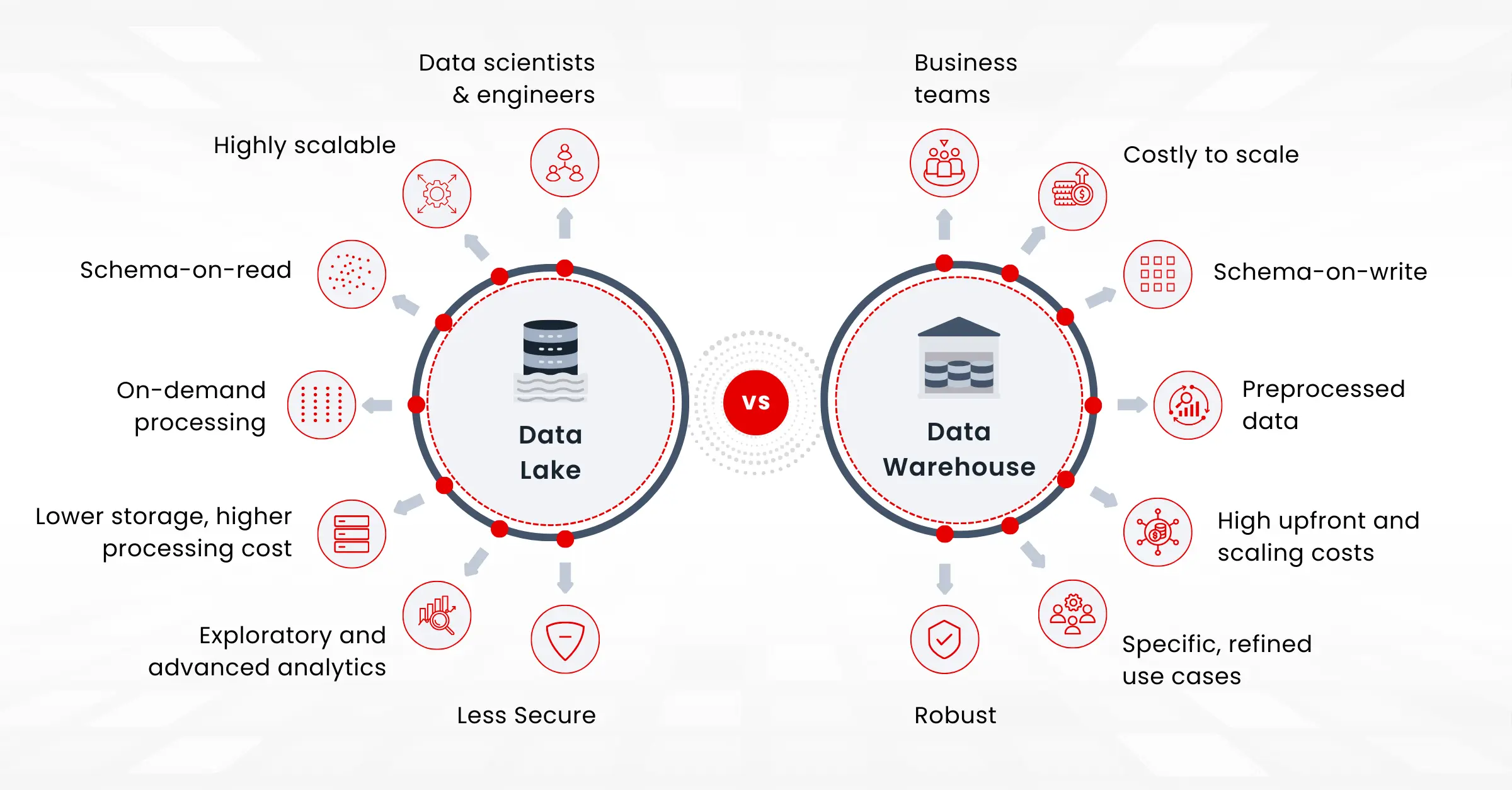
Primary Users
One of the primary distinctions lies in the core users of these systems. Data warehouses are tailored for business intelligence teams who need structured data for reporting and analysis. They rely on clean, regimented data to generate precise insights quickly.
In contrast, data lakes cater to data scientists and engineers who work with raw, unfiltered data to create models. This setup supports advanced calculations, exploratory analysis, and machine learning, offering greater flexibility in handling diverse data types.
Scalability and Performance
Scalability and performance considerations are crucial when choosing between a data lake and a data warehouse. Designed for well-defined data formats, data warehouses ensure fast query performance and retrieval times, making them ideal for generating routine reports based on structured information. However, they can be costly to scale due to the need for sophisticated infrastructure and maintenance.
Data lakes, on the other hand, are designed to store vast amounts of raw data, whether structured, semi-structured, or unstructured. They offer scalability and cost-effectiveness, especially for large datasets. Since raw data is getting processed here, this requires more processing power and can become time consuming.
Structure and Schema
The structure and schema of the data are significant factors. Data warehouses ensure clean and organized data through schema-on-write. By defining the data structure beforehand, data warehouses guarantee that all information is cleaned and formatted correctly before being stored. This leads to higher data quality and faster retrieval times for queries. This method enhances query performance and data consistency but can be rigid and less adaptable to changing data requirements.
Conversely, data lakes use a schema-on-read approach, storing data in its native format without imposing a strict schema. This flexibility allows for more agile data processing and integration of diverse data types, although it might complicate data retrieval and analysis due to the lack of predefined structure.
Data Integration and Processing
Data integration and processing capabilities differ between the two solutions. In data warehouses, data is cleaned, integrated, and processed before storage, ensuring high data quality and efficiency in routine tasks. However, this preprocessing can limit flexibility for complex, ad-hoc analyses.
Data lakes store raw data, deferring processing until the data is accessed for use. This approach, known as schema-on-read, supports complex, real-time processing, making it ideal for advanced analytics and machine learning. This may require more processing power and takes longer.
Cost Implications
Cost implications are another critical consideration. Data warehouses often come with higher upfront costs due to their complex setup and maintenance requirements. They are efficient for structured data and routine queries but can be expensive to scale.
Using commodity hardware to handle large volumes of raw data makes data lakes scalable and affordable. While storage costs are lower, operating expenses can increase if the data requires extensive processing or quality management.
Purpose and Use Case
The intended purpose and use case for the data also influence the choice. Data warehouses are best for refined, specific purposes such as sales reporting, log and event management, or security analysis. They provide structured, processed data that is ready for immediate use.
In contrast, data lakes store raw data for potential future use, supporting applications where comprehensive data exploration and advanced analytics are required. This approach can be beneficial but may lead to longer-term storage costs and challenges in managing large volumes of unfiltered data.
Security
Security is another differentiating factor. Data warehouses, with their mature technology, offer robust security measures for storing structured data. Data lakes, while scalable and flexible, are inherently less secure due to their size and the nature of the raw data stored. However, big data security measures are rapidly evolving, and data lakes are becoming increasingly secure over time.
Key Takeaways
| Feature | Data Warehouse | Date Lake |
| Primary Users | Business Intelligence teams | Data Scientists and Engineers |
| Scalability | Costly to scale | Highly scalable and cost-effective |
| Data Structure | Structured data with predefined schema (schema-on-write) | Raw data with flexible schema (schema-on-read) |
| Processing | Preprocessed data for quick analysis | Raw data processed on-demand |
| Cost | Tracks the cost associated with data storage, processing, and pipelines. Helps optimize spending. | Lower storage costs, higher processing expenses |
| Purpose | Specific, refined use cases | Exploratory and advanced analytics |
| Security | Mature and robust | Evolving, less secure |
Understanding these differences can guide your decision in choosing the most suitable data storage solution for your organization’s needs.
Which Should You Use: A Data Lake or a Data Warehouse?
Selecting between a data lake and a data warehouse hinges on three key factors: your business needs, the structure of your data and its intended use.
Data Lakes: It’s cost-effective for storing data in multiple formats. Ideal for storing massive volumes of diverse data, data lakes cater to businesses that want a cost-effective solution for storing different data formats hoping to leverage raw, unstructured data, such as in machine learning.
Examples: Medical researchers can reanalyze raw datasets for new insights, streaming services can enhance content recommendations, and e-commerce businesses can understand consumer behavior and market trends.
Data Warehouses: It’s ideal for industries with regulatory requirements, standardized reporting, and data that doesn’t change frequently. Designed for structured data and fast insights, data warehouses empower businesses that prioritizes data visualization and rapid analysis and to those who require separation of analytical data from transactional systems.
Example: Financial services benefit from centralizing KYC information, simplifying historical data tracking.
Choosing between a data lake and a data warehouse depends on your organization’s specific needs, data types, and use cases. Data lakes offer a flexible and cost-effective solution for storing diverse data in its raw form, making them ideal for advanced analytics, machine learning, and real-time data processing. They support innovation and exploratory data analysis but require robust data governance to prevent them from becoming data swamps.
On the other hand, data warehouses provide a structured environment for business intelligence activities, ensuring high data quality and fast query performance. They are essential for industries requiring consistent, reliable data for reporting and decision-making but can be more costly and less flexible in handling unstructured data.
Ultimately, the decision should align with your data strategy, considering the types of data you handle, the needs of your users, and your long-term data management goals. By understanding these key differences, you can make an informed choice that maximizes the value of your data investments.
Protect your Data Storage Investment with DQLabs
Regardless of your data storage preference, a modern data quality platform like DQLabs is essential. Data lakes and warehouses alike benefit from DQLabs’ comprehensive approach. It offers over 50+ data quality checks, full-stack observability, lineage tracking, and automated analysis to proactively identify and address data issues. This ensures trust in your data, minimizes downtime, and empowers both business as well as technical users with an intuitive user experience – maximizing the value of your data, wherever it resides.