
Summarize and analyze this article with
As organizations generate massive volumes of data, the need to maintain, organize, and validate this information has never been more important. Think of data curation as digital librarianship–it’s the art and science of organizing data so it remains findable, usable, and valuable throughout its lifecycle.
While traditionally seen as the responsibility of data stewards and curators, data curation now demands attention from the entire data team. Data engineers need to understand curation principles to build data pipelines that maintain data quality. Data architects must consider how curation practices affect system design and data flow. Even data scientists benefit from strong curation practices that give them clean, well-documented datasets for analysis.
In the broader context of data governance, curation serves as the practical implementation of governance policies. It bridges the gap between raw data collection and meaningful business insights by ensuring data is accurately tagged, properly documented, and appropriately accessible.
As organizations recognize the strategic value of well-curated data, many struggle to understand what data curation really means and how it fits into their data management strategy. This blog breaks down the essential elements of data curation, helping you understand not just the ‘what’ but also the ‘how’ and ‘why’ of this critical practice.
Let’s start with the fundamentals.
What is Data Curation?
Data curation is the systematic process of organizing, managing, and enriching datasets to meet the needs of specific groups of users. It involves transforming raw data into structured, accessible, and usable formats that enhance the value and usability of the data.
The ultimate goal of data curation is to reduce the time from data discovery to actionable insights. It ensures that business users, researchers, or analysts can quickly locate and utilize data to its full potential, making informed decision-making faster and easier.
Data curation comes handy across many industries. Here are some of the examples which shows its significance:
- Scientific Research: Enables collaboration and faster discoveries by preserving and organizing data in fields like genomics, climate studies, and physics.
- Healthcare: Patient records are categorized for easy access, archived for long-term use, encrypted for security, and cleaned to ensure accurate medical decisions.
- Finance: Transaction data is organized, retained for audits, protected with encryption, and standardized for clear reporting, reducing fraud risks and increasing transparency.
- Government Records: Essential records are indexed, digitized for preservation, safeguarded with controlled access, and enriched with metadata for usability.
- Machine Learning: Improves algorithm performance by structuring the training data, archiving it for reuse, and labelling it to improve algorithm accuracy.
Why is Data Curation Important?
Data curation is important because it organizes and manages raw data to ensure quality, accessibility, and usability. By curating data, organizations prevent inefficiencies like data silos, poor-quality data, and disorganized records, which can lead to errors and missed opportunities. It bridges gaps between data existence and use, ensuring employees can find and trust the data they need.
For example, curated data enables accurate inventory tracking for retailers, reliable patient records in healthcare, and high-quality metadata in research and finance. Without data curation, businesses risk wasted resources, compromised decisions, and lost insights.
Data curation enhances efficiency for both data engineers and data consumers. Without curation, data engineers would face redundant rework, repeatedly building custom pipelines and transforming the same raw data for every request. This not only wastes time and resources but also creates bottlenecks, emphasizing the need for some level of data self-service.
At the same time, providing unrestricted access to raw data can overwhelm non-technical users, leading to errors, inconsistent metrics, and misinterpretations due to a lack of business logic or source system understanding. Data curation strikes a balance by transforming, enriching, and organizing data that supports widespread usability and consistency across your data teams.
Curation also provides a staging area for experimentation, allowing data teams to work through the complexities of development without impacting production systems. However, it comes at a cost. Each layer of curation adds exponential expenses, making it necessary for data leaders to focus curation efforts on high-value use cases and avoid over-curating data. Prioritizing and tailoring curation to specific needs ensures both efficiency and cost-effectiveness.
Steps Involved in the Data Curation Process
Data curation involves several steps to transform raw data into usable assets.
Step 1: Data Collection and Ingestion
The process starts with data collection, where data is gathered from multiple sources according to organizational needs and standards. This collected data then moves through ingestion pipelines into central repositories or data warehouses. Quality assessment follows, which focuses on checking data accuracy, completeness, and consistency.
Step 2: Metadata Creation and Documentation
The next phase involves creating detailed metadata that provides context and understanding of the data, followed by cataloging to organize datasets for easy discovery. This makes it easier for data discovery and retrieval. Comprehensive documentation is created, including data dictionaries and transformation logic, to help users understand and utilize the data.
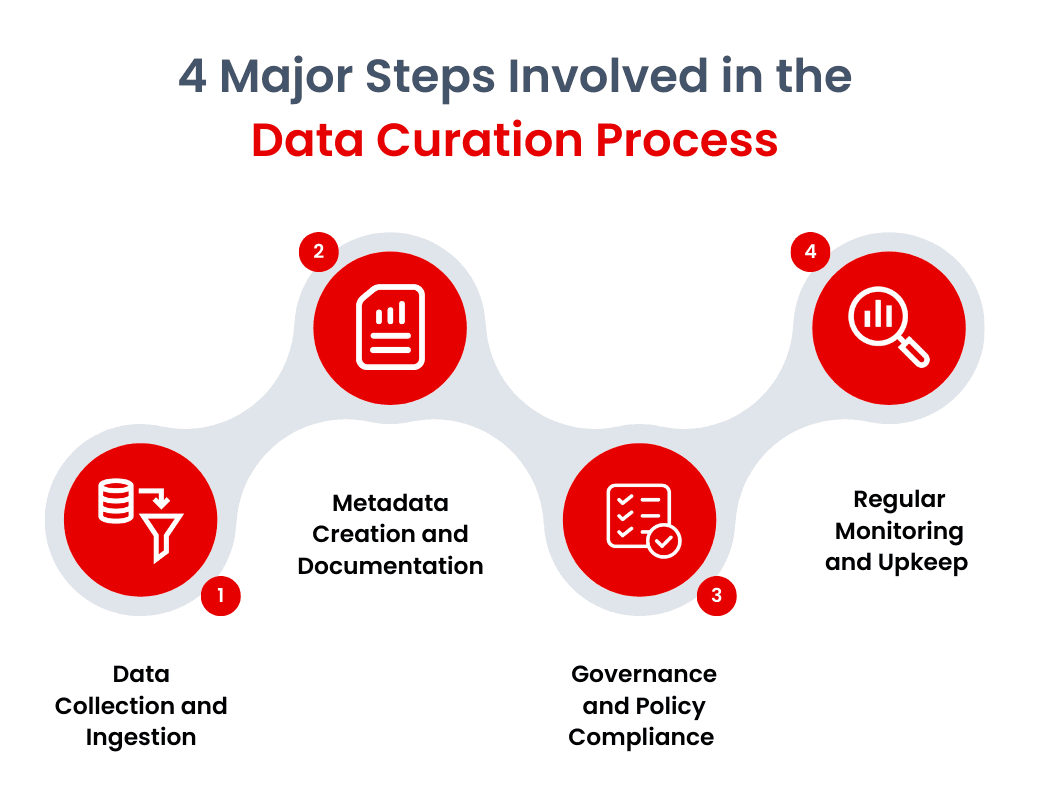
Step 3: Governance and Policy Compliance
This process includes establishing data governance policies that align with organizational goals and regulatory requirements. Data validation systems monitor accuracy and consistency, while data lineage tracking helps identify the origin and flow of data throughout its lifecycle. Privacy measures are put in place through encryption techniques and role-based permissions.
Step 4: Regular Monitoring and Upkeep
Regular monitoring and maintenance keep the data accurate and relevant, with metrics configured to measure data accuracy and identify areas for improvement. Data enrichment adds valuable context through additional information and tags, while preservation techniques maintain long-term data reliability and accessibility.
Each of these components works together as part of an integrated system to create a data management framework that supports organizational needs while maintaining data quality and security.
Key Differences Between Data Curation and Data Cleaning
Data curation and data cleaning are often misunderstood, but both are integral to any analytic infrastructure. Hence, understanding the differences between these processes is important. The following table illustrates some of the key differences between them:
| Aspect | Data Curation | Data Cleaning |
| Definition | The process of collecting, organizing, managing, and preserving data for usability and accessibility. | Title, Author, Subject, Genre, Publication date |
| Scope | Broader process encompassing collection, cleaning, organization, metadata creation, and preservation. | Narrower focus on improving data quality by correcting errors and removing inaccuracies. |
| Objective | To make data usable, accessible, well-documented, and organized for analysis or future use. | To ensure data accuracy, reliability, and consistency for immediate use. |
| Activities Involved | Includes data collection, ingestion, cataloging, governance, enrichment, and maintenance. | Involves detecting and resolving duplicates, missing values, and formatting errors. |
| Tools Used | Data catalogs, metadata management tools, governance platforms. | Data quality tools, ETL (Extract, Transform, Load) tools, and manual corrections. |
| Use Cases and Examples | Creating data catalogs, preserving clinical trial data, or organizing research datasets. | Fixing inconsistent customer records or correcting formatting errors in transaction data. |
| Outcome | Structured, enriched, and reusable datasets with added metadata for discovery and context. | High-quality, accurate, and reliable data free from errors or inconsistencies. |
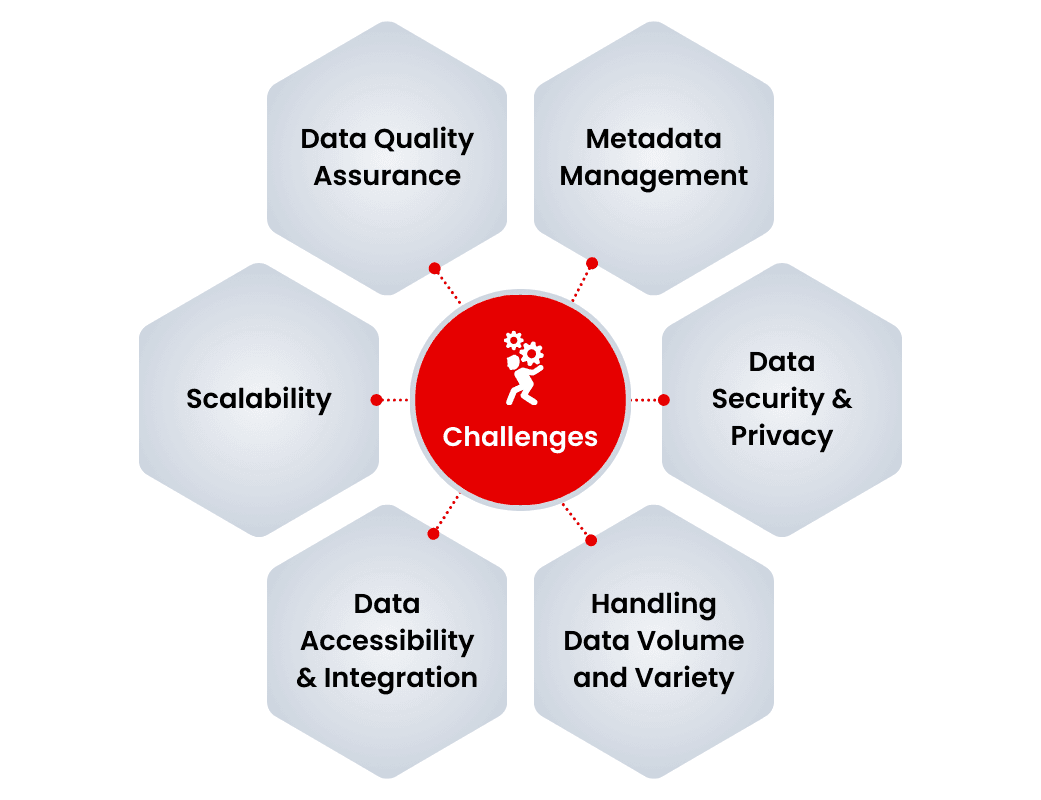
Major Challenges in Data Curation and Suggestions to Overcome Them
Data curation involves several challenges that need to be addressed to manage and utilize data effectively. Tackling these issues strategically is critical for maintaining data usability and value.
- Data Quality Assurance: Maintaining accurate, consistent, and reliable data is a key challenge, particularly when working with multiple data sources. Errors, inconsistencies, and outdated records can affect analysis and decision-making. Regular audits and data profiling tools can help improve data quality.
- Metadata Management: Managing and updating metadata for all datasets can become overwhelming, especially with rapidly growing data volumes. Metadata provides context and makes data easier to understand. Automated metadata tools can simplify this process and maintain consistency.
- Data Security and Privacy: Protecting sensitive data while meeting compliance requirements is complex. Unauthorized access and breaches can create serious issues. Robust governance policies, encryption techniques, and role-based access controls help manage data access securely.
- Handling Data Volume and Variety: Curating large volumes of structured, semi-structured, and unstructured data presents challenges in organization and classification. Tools like data catalogs and automated tagging systems can streamline this process and help prioritize data based on relevance.
- Data Accessibility and Integration: Siloed data and poor integration limit the ability to access and use datasets efficiently. Centralized data repositories and catalogs improve access and allow for better collaboration across teams and departments.
- Scalability: As datasets expand, scaling infrastructure to handle storage, schema changes, and processing becomes a challenge. Scalable processing tools and real-time update systems are essential for managing growing data volumes effectively.
Addressing these challenges with proper tools and clear processes ensures curated data remains valuable and relevant for business use.
Best Practices for Data Curation
Effective data curation combines strategic methodologies and advanced tools to manage and utilize data efficiently. Below are some key practices to enhance data curation efforts:
- Understand Data Context and Usage: Before initiating curation, it is essential to understand what the data represents, its relevance to business processes, and how it will be used. Creating context through comprehensive documentation, such as metadata and cross-referenced information, ensures the data’s purpose is clear and actionable.
- Develop Governance and Access Policies: Clear governance policies help standardize data handling across departments. This includes implementing access controls to manage sensitive information and granting privileges only where necessary. Adopting a “least privileged access” approach minimizes risks and supports compliance with regulations.
- Regularly Audit and Update Data: Routine quality checks are necessary to identify outdated, redundant, or inaccurate records. Updating metadata and propagating changes across all linked datasets ensures data remains consistent and reliable for users.
- Promote Collaboration and Communication: Cross-departmental collaboration between analysts, data scientists, and business users fosters a shared understanding of data. Transparent communication through shared channels, such as Slack, facilitates efficient data discovery and issue resolution.
- Automate Where Possible: Automation becomes essential when managing large datasets. Tools like data catalogs automate metadata creation, data discovery, and lineage tracking, saving time and reducing manual errors. Automation also supports prioritization by identifying high-value data.
By combining these best practices with advanced tools, organizations can streamline data curation processes, making data accurate, accessible, and strategically valuable.
How DQLabs Helps you Simplify Data Curation
Data curation is needed for effective governance and data management strategies, and platforms like DQLabs simplify this process. With advanced metadata management, cataloging, and AI-powered automation, DQLabs simplifies data curation. Its Active Semantic Classification automates tagging and discovery, while semantic search and real-time observability ensure curated data is accurate, accessible, and aligned with business objectives. Collaboration features and compliance frameworks further enhance usability and security, making curated data actionable and reliable.
Don’t take our word for it, see it in action. Talk to an expert today!