
Summarize and analyze this article with
Databricks is a cloud-based data platform that integrates data engineering, machine learning, and analytics into a unified workspace. Built on Apache Spark, it enables organizations to efficiently process and analyze large datasets. The platform supports a variety of data formats and provides tools for real-time data processing, making it suitable for diverse applications, including data preparation and machine learning model development. Databricks’ architecture promotes collaboration among data scientists, engineers, and analysts, streamlining workflows and enhancing productivity. Its unique Lakehouse model combines the best features of data lakes and warehouses, addressing the complexities of modern data management.
The Need for Automated Data Quality Management in Databricks
Data in Databricks often originates from diverse sources, each with its own format and potential inconsistencies. This variability poses significant challenges in maintaining a uniform standard of data quality throughout the data lifecycle. Maintaining high data quality in Databricks often depends on the expertise of its users. Without skilled personnel who understand the nuances of data validation and quality management, organizations may struggle to preserve the integrity of their data. Although Databricks supports integration with external tools for data quality management, its native capabilities may not provide the comprehensive end-to-end observability required by some organizations. As a result, users often rely on third-party solutions to achieve a holistic view of data quality across their pipelines.
Managing data quality and observability is further complicated by the need for a robust data governance framework. While Databricks provides cataloging and governance for its assets, it falls short in governing non-Databricks sources and assets. Additionally, Databricks requires SQL queries for data management, which isn’t ideal for non-technical users who must rely on engineering for data discovery and permissions. Databricks also lacks personalized access policies, making it difficult to set and monitor policies as data consumers’ needs become more complex. Defining policies by business domains, user personas, or projects is a better approach, but Databricks doesn’t support this. Additionally, manually setting access permissions for data assets across various applications isn’t feasible, highlighting the need for auto-propagation via lineage mapping. Finally, compliance with regulations like GDPR or CCPA demands that sensitive data be masked or hashed, yet Databricks lacks the built-in capabilities to do this easily.
Read: Learn how data quality management is simplified using DQLabs.
How DQLabs Integrates with Databricks
DQLabs allows users to easily discover and profile data assets within their Databricks environment. Users can search for specific data (e.g., email information) across all organizational assets, including those stored in S3 and managed through Glue Data Catalog or Tableau. The platform supports out-of-the-box capabilities for data profiling, enabling users to assess data quality across different stages of processing (bronze, silver, gold) within Databricks, without extensive coding. DQLabs can utilize Databricks’ compute power by running Spark SQL queries or leveraging the existing Spark instance, allowing for processing without moving data out of Databricks. DQLabs allows users to select specific attributes of interest, focusing on business-critical data rather than analyzing the entire dataset. This targeted approach helps avoid overwhelming the system with unnecessary information.
Managing Data Quality in Databricks with DQLabs
Automated Data Profiling and Cataloging
DQLabs for Databricks stands out for its automated data profiling and cataloging capabilities. As data volumes grow, traditional methods of managing and understanding data become inefficient. DQLabs integrates seamlessly with Databricks to automate the profiling and cataloging of data assets, reducing manual effort and enhancing data discovery.
The out-of-the-box data quality scoring feature allows users to quickly assess the quality of their data using predefined scoring metrics. The system automatically profiles datasets and assigns scores based on various quality dimensions, such as completeness, accuracy, consistency, validity, timeliness and uniqueness. This immediate assessment provides users with a clear understanding of their data’s reliability and readiness for further analysis. By utilizing these pre-configured scoring models, organizations can rapidly identify and address data quality issues without the need for extensive manual configuration, ensuring consistent data quality.
Customizable Data Quality Rules
DQLabs provides users with the ability to define and customize data quality rules to suit their specific business requirements. This flexibility allows organizations to set parameters for various data quality dimensions, such as accuracy, timeliness, and consistency, tailored to their unique data needs. Users can dynamically adjust these rules based on changing business contexts or evolving data governance policies. This level of customization ensures that data quality efforts are closely aligned with organizational goals and can adapt to new challenges as they arise. With no-code option, even business users can easily create these data quality rules without having to rely on technical personnel.
Intelligent Metadata Enrichment
Metadata plays a vital role in managing data assets, and DQLabs takes it further with intelligent metadata enrichment. By leveraging advanced algorithms, DQLabs infers additional properties and relationships within the data, automatically identifying and tagging sensitive information. This ensures compliance and enhances data governance, improving discoverability and overall data quality.
In Databricks, DQLabs automates data cataloging through smart data sensing and metadata creation. It detects and extracts metadata from structured sources, identifying key properties like partition keys and data types. This automation eliminates manual entry, reduces errors, and speeds up data onboarding, ensuring that metadata remains accurate and up-to-date for effective data management. By ensuring that metadata is always up-to-date and comprehensive, DQLabs helps organizations maintain an accurate and accessible data catalog.
Semantic Discovery
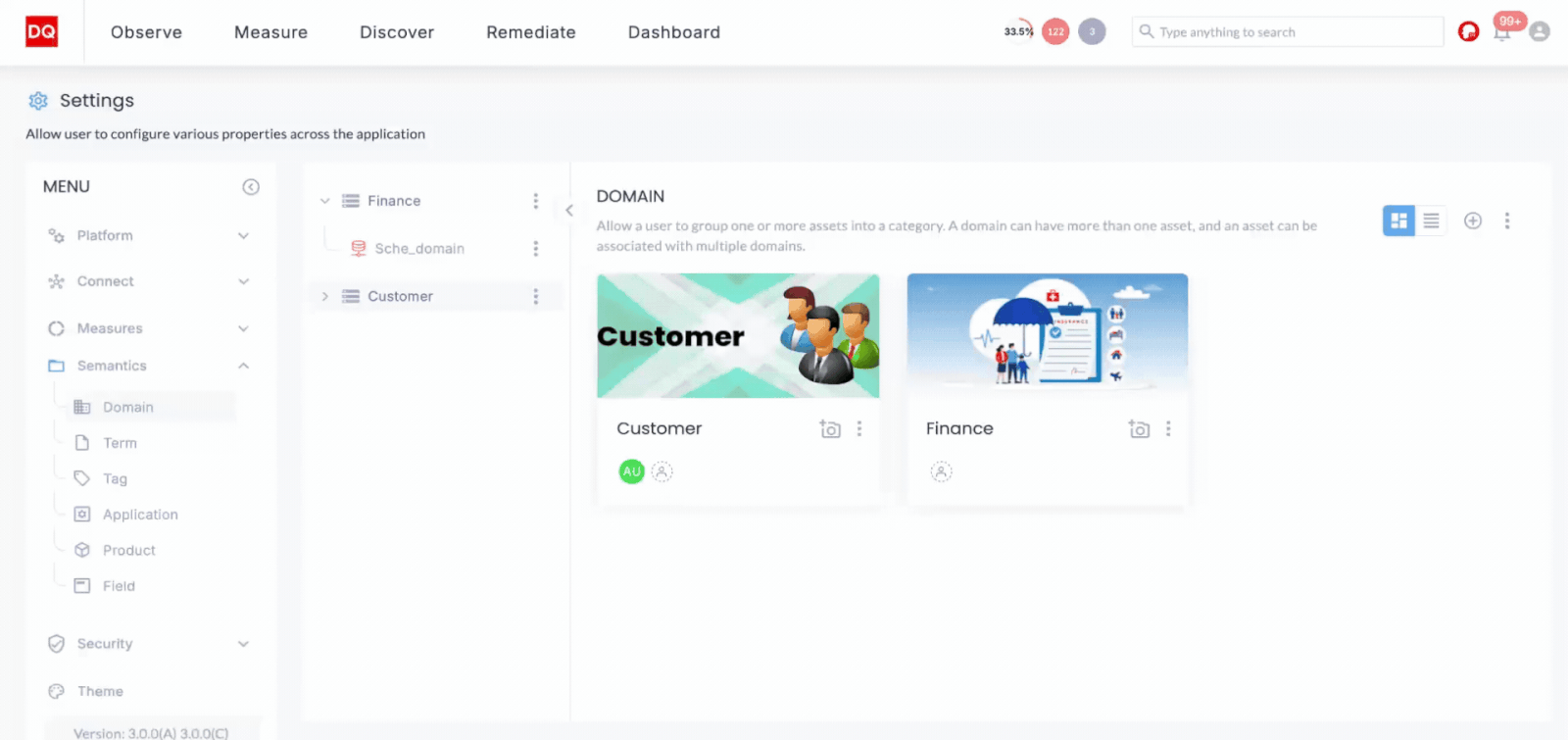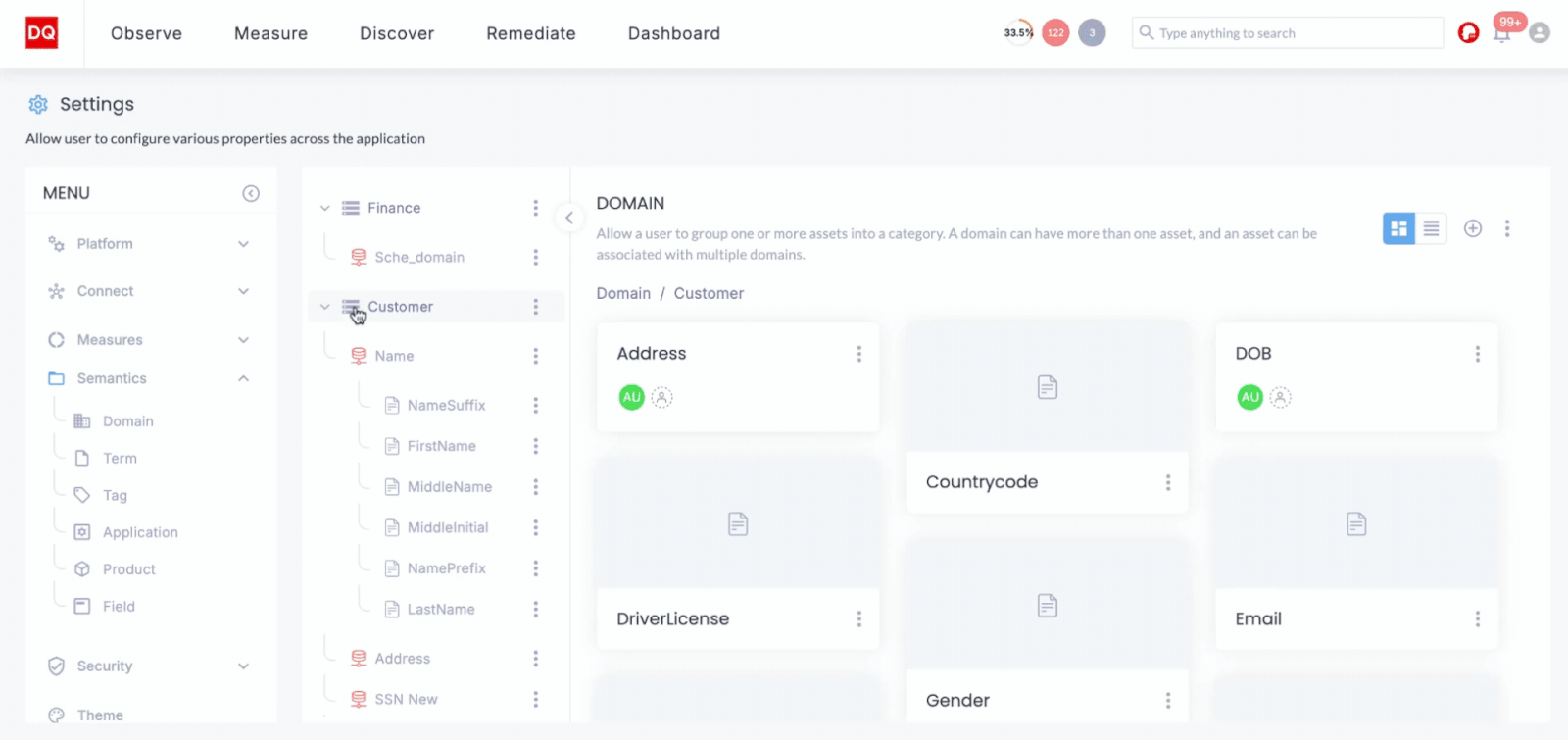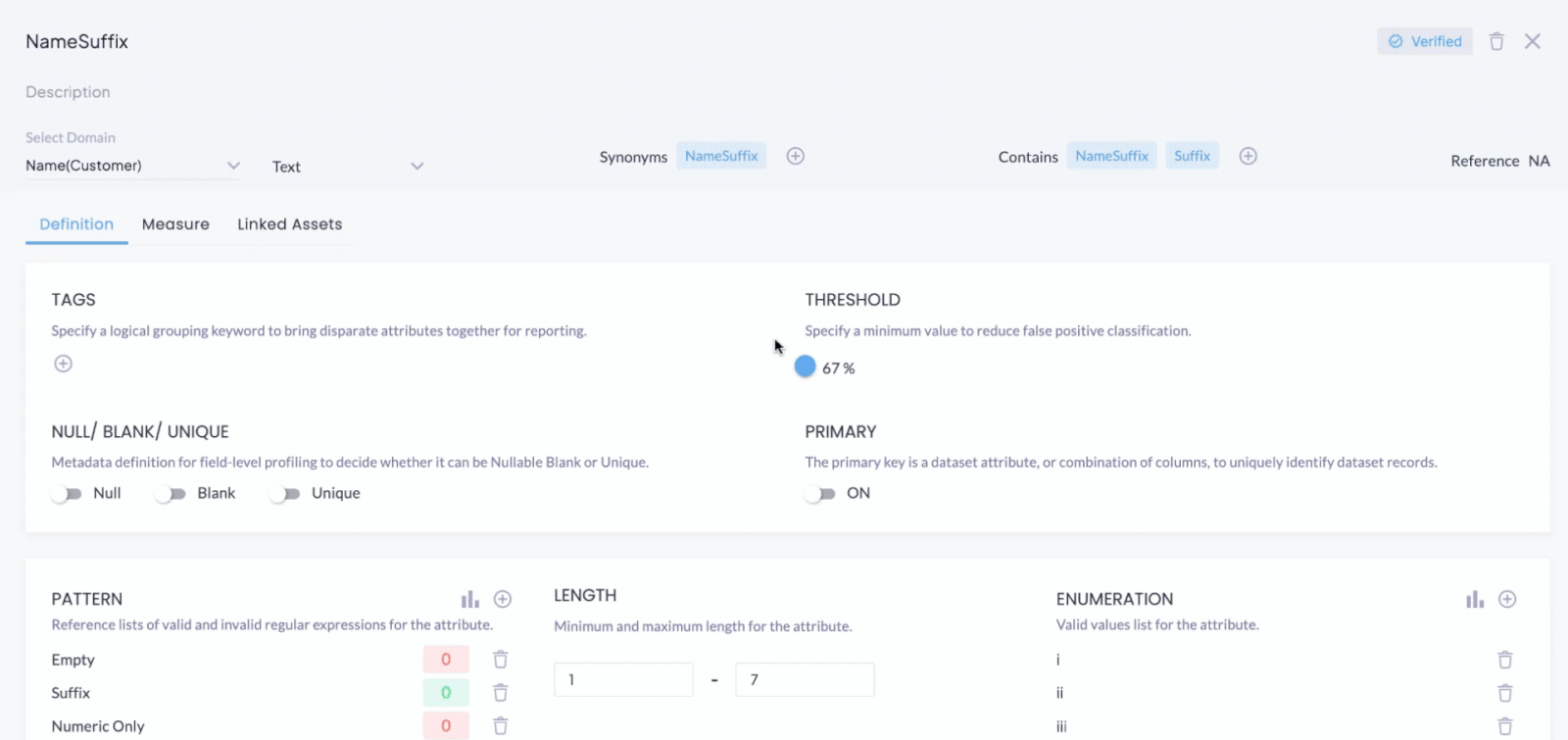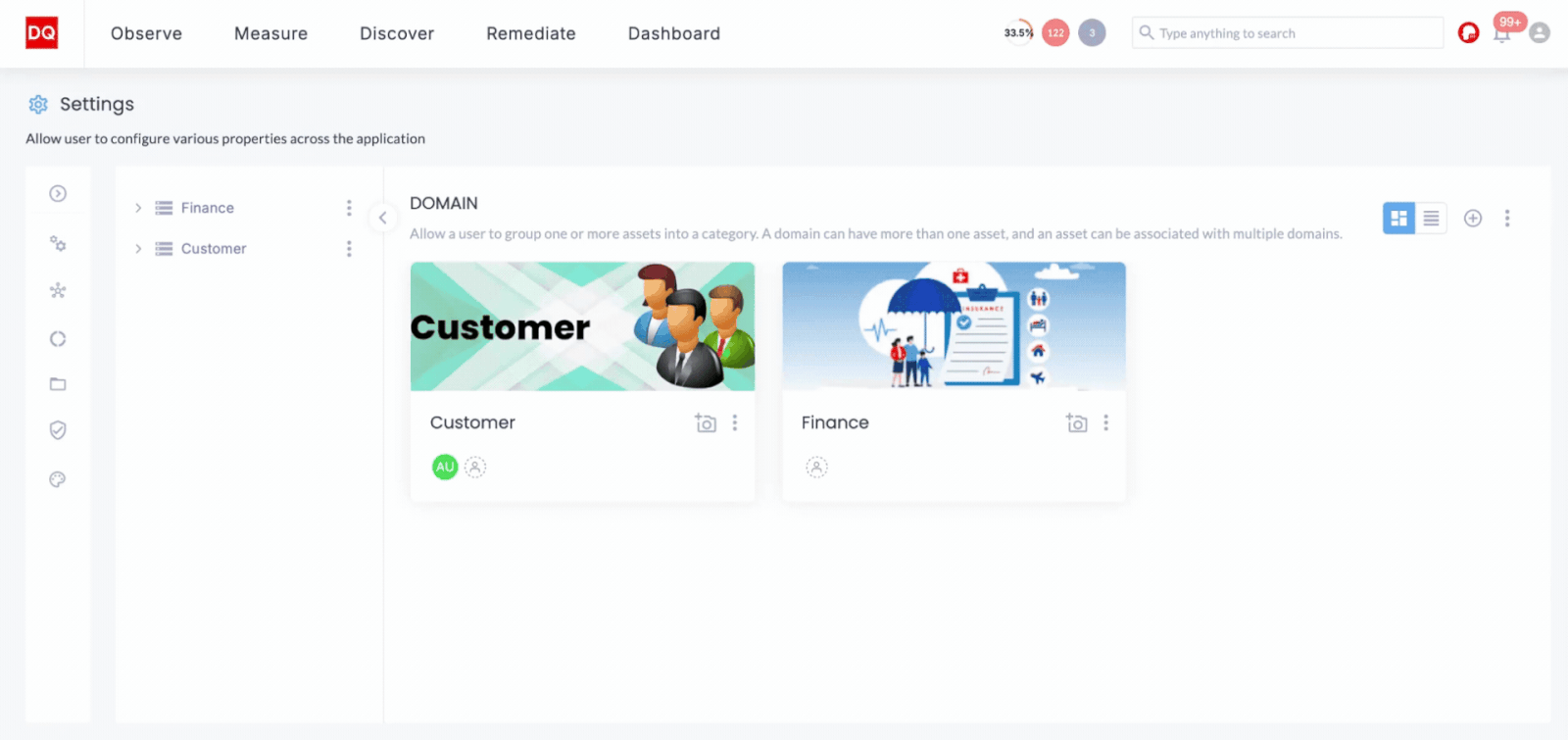
Semantic understanding of data is essential for ensuring that data is used correctly within its context and semantic search can be a powerful capability to have in your Databricks environment. DQLabs uses semantic layers, enabling organizations to apply domain-specific semantics to their data. This is particularly valuable for industries like finance or healthcare, where the meaning of data can vary significantly. By incorporating semantic layers, DQLabs allows users to create and apply customized semantic rules that align with their business needs, reducing miscommunication and enhancing the accuracy of data-driven decisions. Our platform automatically discovers key elements, including business terms, domain-and-department-specific glossaries, existing rules, policies, classification tags,and user-generated semantics.
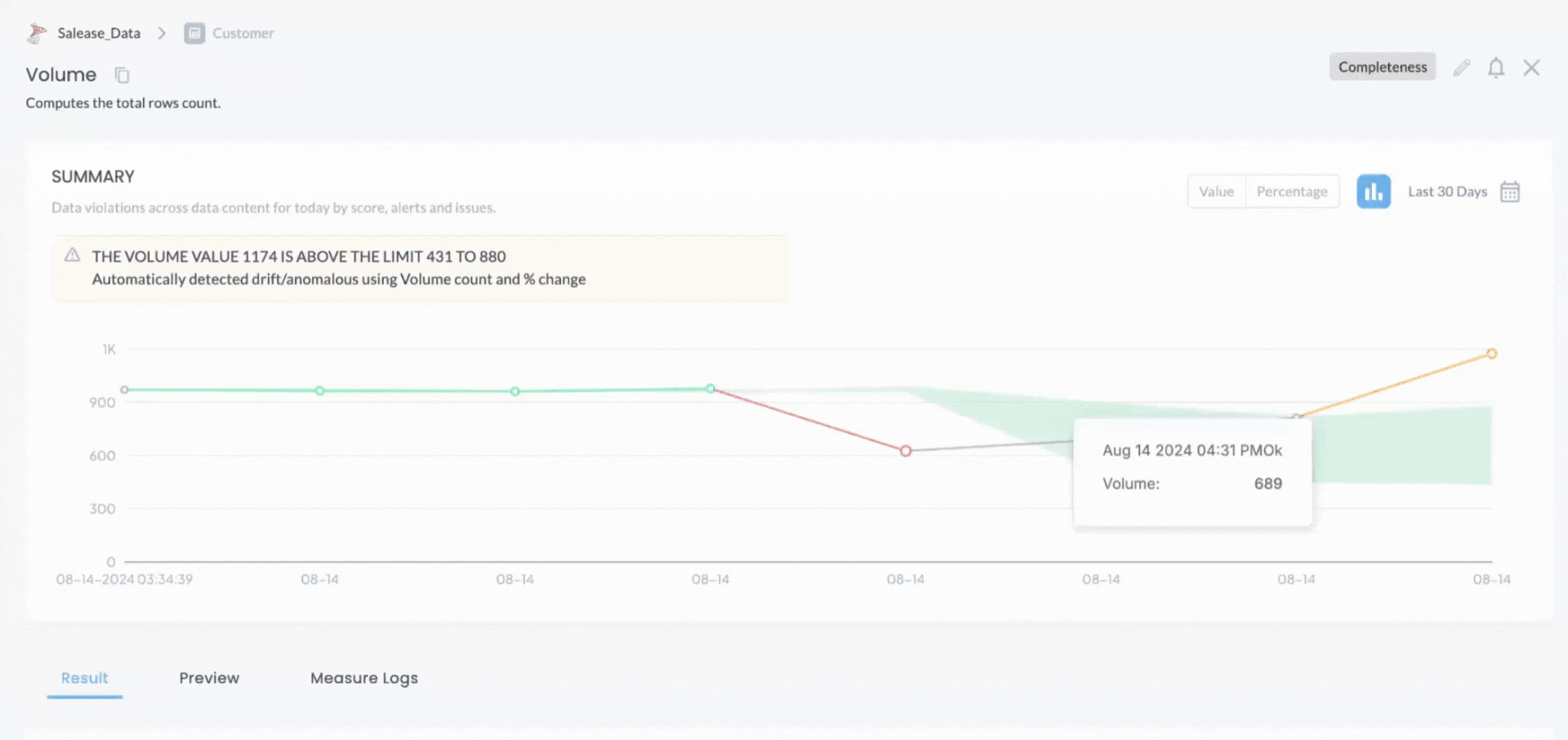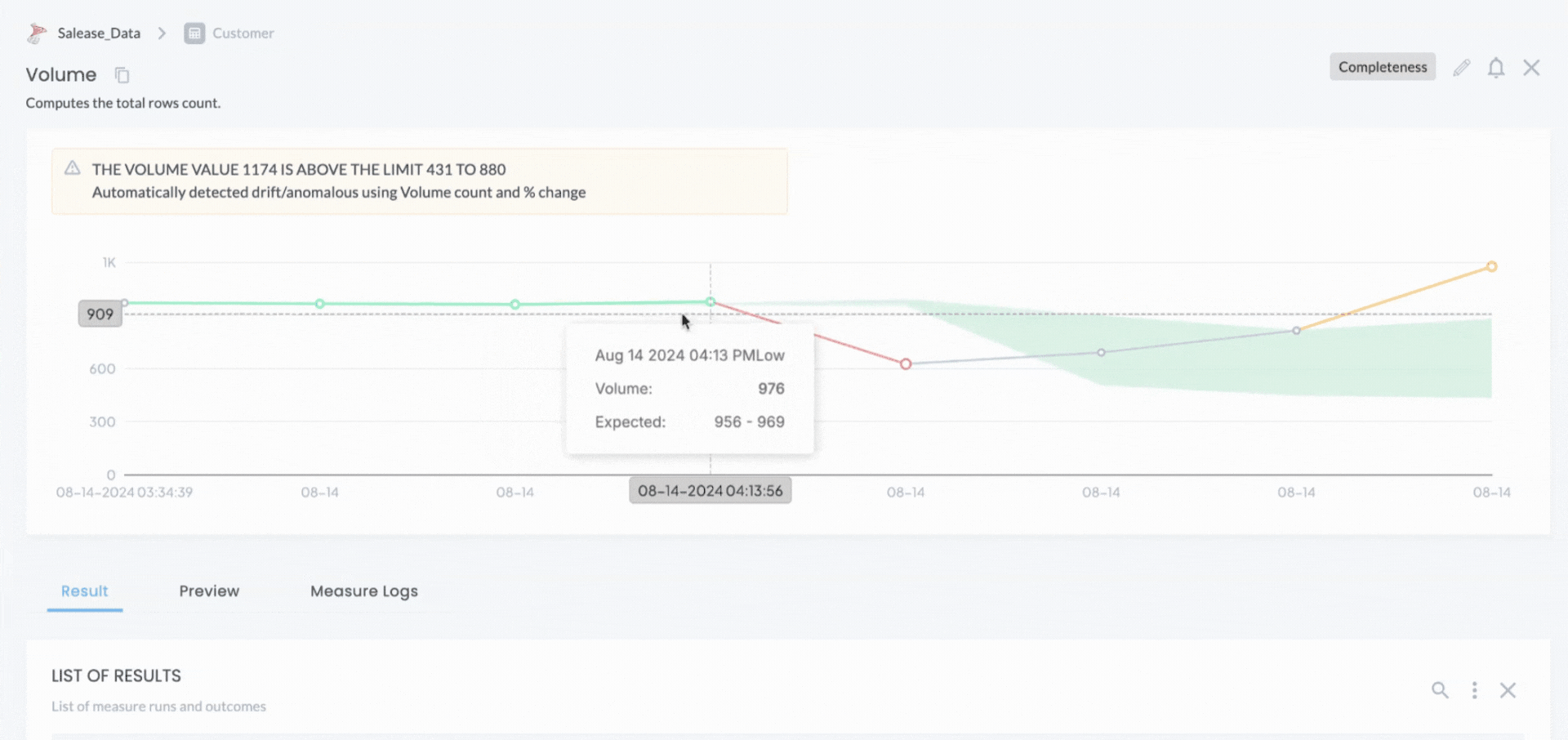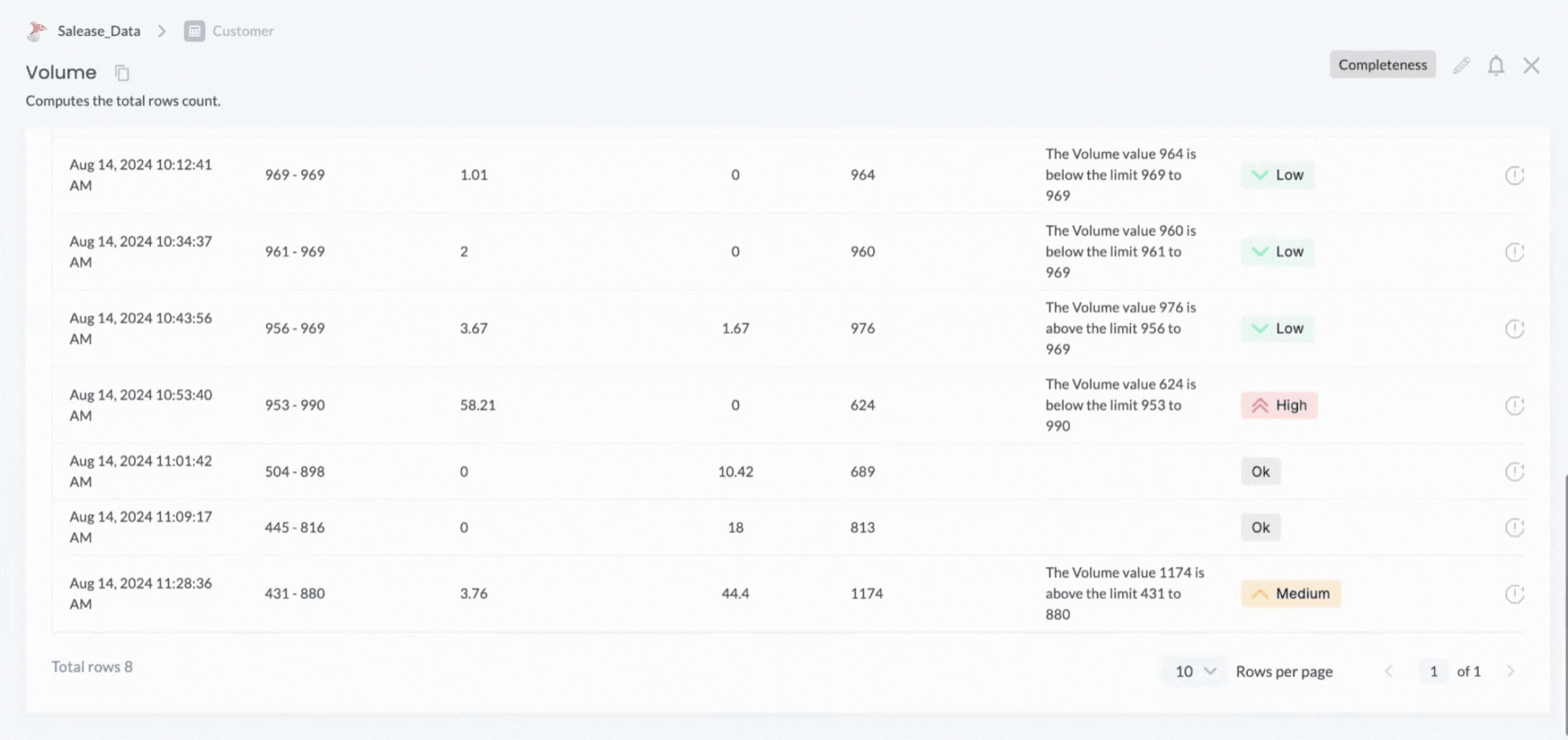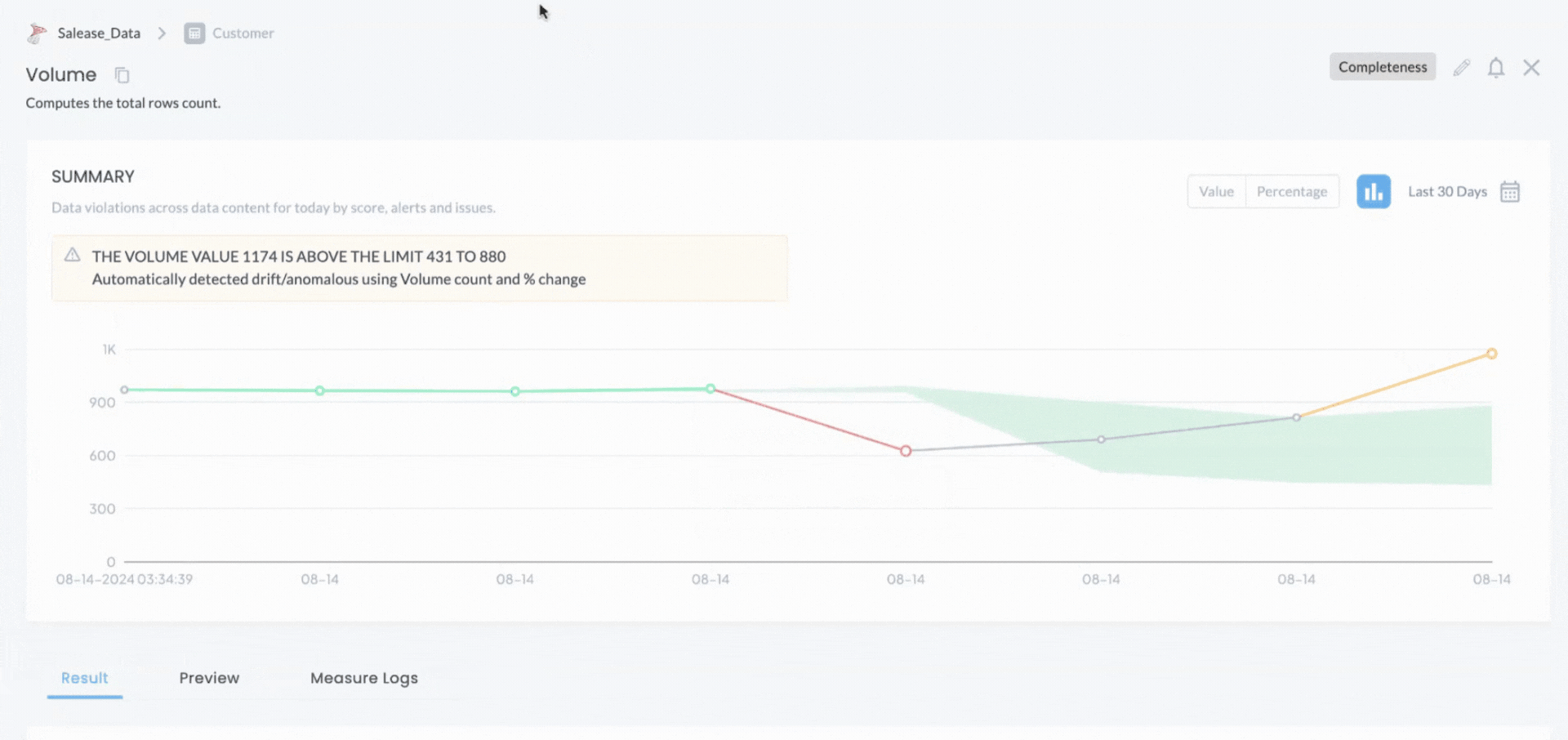
Anomaly Detection and Drift Analysis
Maintaining data quality over time is a continuous challenge, especially as data evolves. DQLabs addresses this with its Anomaly Detection and Drift Analysis features, which enable organizations to monitor data in real-time, automatically detecting anomalies and data drift. For instance, DQLabs can identify when the distribution of data values in a dataset changes unexpectedly, prompting a review to ensure the data remains accurate and reliable. This proactive approach helps organizations catch issues early, minimizing the impact on downstream processes.
Schema drift information is seamlessly incorporated into our active metadata module or any third-party data catalog (such as Alation and Collibra), ensuring that data structures are always current. This keeps the catalog up-to-date, helping users make informed decisions about data utilization.
Custom Dashboards and Reporting
DQLabs for Databricks includes customizable dashboards and reporting features that allow users to create tailored views of their data quality metrics. These dashboards can be configured to display relevant information for different stakeholders, whether it’s a high-level overview for executives or detailed metrics for data engineers. The reporting capabilities in DQLabs enable users to generate insights that can be shared across the organization, ensuring that everyone has access to the data they need to make informed decisions.
Integration with Existing Infrastructure
DQLabs supports seamless integration with a wide range of third-party tools and services, including popular issue management systems like Jira and BigPanda. This integration allows organizations to streamline their data quality workflows and reporting processes. By integrating with existing infrastructure, DQLabs enables users to manage data quality issues within their current operational frameworks, reducing the learning curve and improving efficiency. This integration ensures that data quality management becomes part of the broader data governance strategy rather than a siloed effort.
Flexible API Integration
DQLabs offers great API integration options, allowing organizations to incorporate its data quality features directly into their data pipelines and automated workflows. This API access provides developers with the tools needed to embed data quality checks, anomaly detection, and other DQLabs functionalities into custom applications or processes. By leveraging API integration, organizations can automate repetitive tasks, enforce data quality standards consistently across different platforms, and ensure that data remains reliable throughout its lifecycle.
Configurable Notifications and Alerts
DQLabs provides configurable notifications and alerts, allowing users to set custom thresholds for different data quality events. These alerts can be tailored to the needs of different stakeholders, ensuring that the right people are informed at the right time without overwhelming them with unnecessary notifications.
DQLabs also uses machine learning models to monitor data drift using historical records. For each measure run, the actual values are fed into ML models based on the defined anomaly settings. When the minimum limit set in these settings is reached, the models calculate the expected upper and lower thresholds. If the actual value falls outside this expected range, an alert is triggered. Users can configure the minimum look-back period or the number of runs that the ML models should consider when determining these thresholds.
Business Impact & Benefits of Automating Data Quality Management in Databricks
Operational Efficiency
DQLabs automates data profiling, cataloging, and quality checks, ensuring that decision-makers have access to reliable, accurate data. By eliminating manual data validation processes, DQLabs significantly reduces the time it takes to prepare data for analysis. This acceleration in data readiness allows businesses to make timely decisions, capitalize on market opportunities, and respond swiftly to challenges.
Additionally, automated data quality management improves operational efficiency by reducing the burden on IT and data management teams. Routine tasks such as data profiling, anomaly detection, and metadata enrichment are handled automatically by DQLabs, freeing up valuable human resources to focus on more strategic initiatives. This not only enhances productivity but also leads to cost savings, as fewer resources are needed to manage data quality.
Risk Mitigation and Compliance Assurance
DQLabs’ automated data quality management features, such as intelligent metadata enrichment and data governance features, help businesses stay compliant by continuously monitoring data for adherence to regulatory standards. The platform automatically detects and flags potential compliance issues, enabling businesses to address them proactively. This reduces the risk of non-compliance and helps maintain the integrity of data across the organization.
Moreover, DQLabs’ anomaly detection and drift analysis capabilities provide ongoing monitoring of data to ensure that it remains consistent and reliable. By identifying deviations in data patterns early, businesses can take corrective action before these anomalies lead to significant issues, such as financial losses or operational disruptions. This proactive approach to risk management is essential in maintaining the trust and confidence of stakeholders.
Scalability and Flexibility
As businesses grow and expand, their data environments become increasingly complex. The sheer volume and variety of data can overwhelm traditional data management processes, leading to inefficiencies and data quality degradation. DQLabs is designed to scale with the organization, handling large datasets across various platforms, including cloud environments like Databricks.
The platform’s ability to automate data quality management ensures that businesses can maintain high data quality standards regardless of scale. This scalability is particularly important for organizations that are undergoing digital transformation or expanding their operations into new markets. DQLabs’ flexible API integration also allows businesses to seamlessly incorporate its data quality features into existing data pipelines and workflows, ensuring consistent data quality across all business processes.
Conclusion
DQLabs empowers organizations to innovate faster by providing high-quality data that enables advanced analytics, machine learning models, and AI-driven initiatives. With DQLabs, businesses can experiment with new data-driven strategies with confidence, knowing that the underlying data is accurate and reliable. Furthermore, the automation of data quality management reduces the time and effort required to bring new data products and services to market. This agility allows businesses to outpace competitors, deliver superior customer experiences, and drive revenue growth.
If you are looking for best-in-class data quality management solution for your databricks sources, try DQLabs – a leader in the Everest PEAK Matrix® Assessment 2024 for Data Observability Technology Providers and has been positioned by Gartner® as a Niche Player in the Magic Quadrant™ for Augmented Data Quality Solutions.
Experience Augmented Data Quality and Data Observability firsthand. Schedule a personalized demo today.