
Summarize and analyze this article with
Data is increasingly becoming the driving force of every organization in the modern world. Organizations want to leverage their data landscape to ensure that data-driven decision-making is a core part of their business operations.
However, bad quality data is one of the biggest challenges in implementing robust data-driven decision-making. Data, right from its source, and through the process of making it consumable, often ends up being erroneous, incomplete, stale, and inconsistent. When this data reaches downstream systems and applications, it can lead to faulty analyses, AI/ML models’ failure, and severe cost implications.
In this context, data pipelines are one of the most important elements of the modern data stack. They are the first components that have access to poor quality data and can potentially send this incorrect data to downstream systems and applications. Implementing a data quality validation process in the data pipelines is, therefore, one of the ideal ways to deal with data quality issues proactively.
One of the best methods to ensure robust data quality validation is to integrate data pipeline tools with data quality platforms. By doing so, organizations can easily implement quality checks throughout the data pipeline and catch them early on. Through the course of this article, we will explore more about how this works.
Benefits of Integrating Data Pipelines with Data Quality Platforms
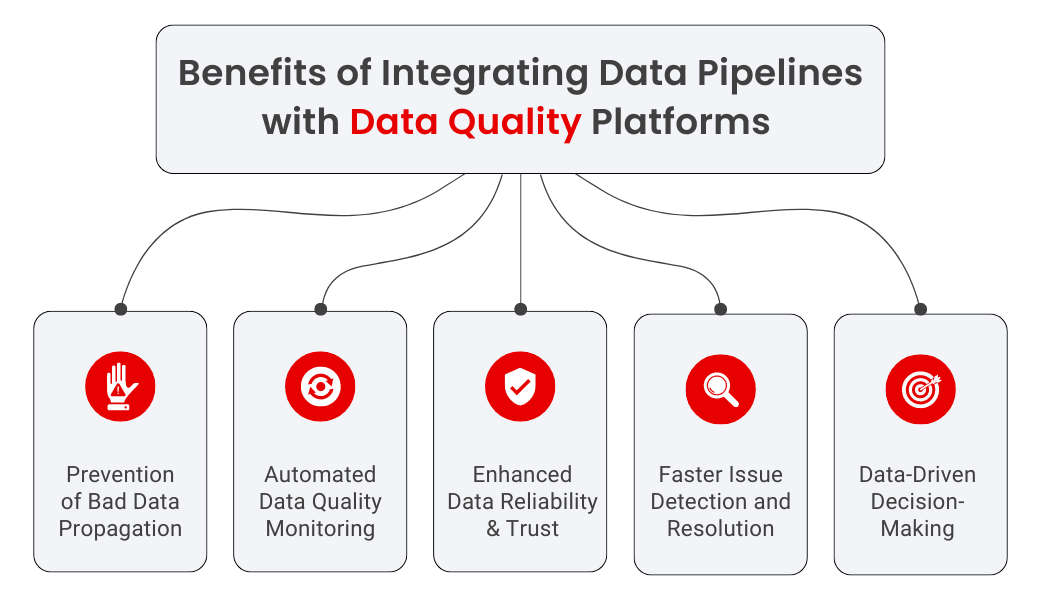
- Prevention of Bad Data Propagation: By integrating data pipelines with a data quality platform, you can detect and stop the flow of bad or erroneous data before it enters downstream systems like fact and target tables. This ensures that faulty data doesn’t propagate through the pipeline and affect critical business decisions, avoiding costly errors in analytics, reporting, and operations.
- Automated Data Quality Monitoring: Integration enables continuous, automated data quality checks at every stage of the pipeline—starting from the source table through to the fact and target tables. This automation helps to quickly identify and resolve issues like data schema changes, missing values, or inconsistencies without manual intervention, increasing efficiency and reducing errors.
- Enhanced Data Reliability and Trust: The integration improves the overall trust in your data by ensuring that only clean, validated, and high-quality data makes it to the end destination. Data consumers, including business analysts and decision-makers, can rely on the fact that the data they are using is accurate, consistent, and up-to-date, enabling better decision-making.
- Faster Issue Detection and Resolution: When data pipelines are integrated with a data quality platform, issues are flagged in real-time as data moves from one stage to another. This reduces the time taken to detect and resolve issues, ensuring minimal downtime for the data pipeline. You can also set automated alerts that notify teams when data quality falls below predefined thresholds, allowing for swift action.
- Data-Driven Decision-Making: By ensuring high quality and trusted data, organizations can confidently make business decisions based on trustworthy and high-quality data. Data and business teams can trust organizations’ data landscape, which leads to increased data utilization and promotes data-driven decision-making.
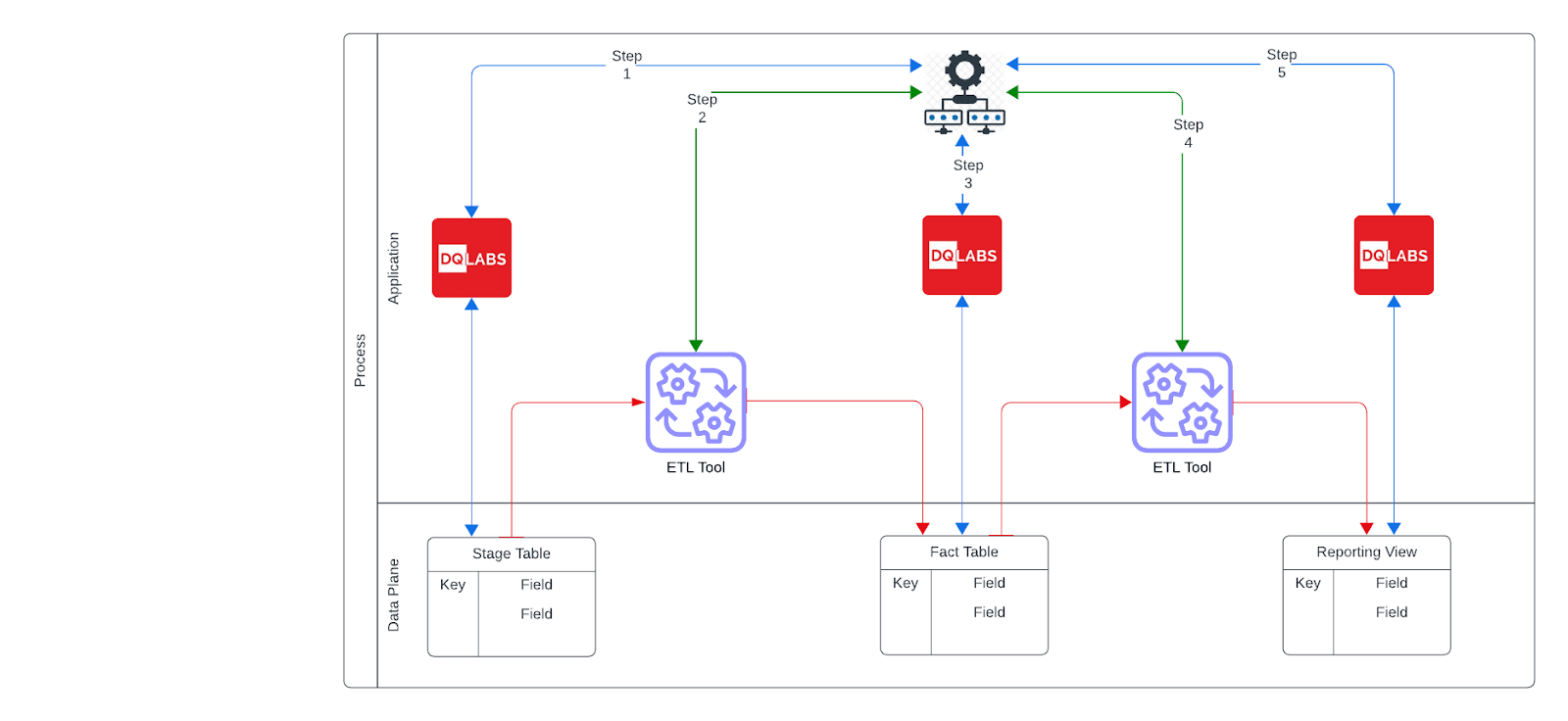
Integrating DQ Checks In Data Pipelines
- Check last known data quality status: The data pipeline begins by making an API call to the data quality platform to check the status of the last known data quality issues at the source table, where raw data originates. This step is crucial to ensure that any previously identified problems, such as missing or incorrect values, are acknowledged before the pipeline continues. If the API detects any critical issues, the pipeline can stop, preventing potentially bad data from moving downstream into the fact table or the target table. This early check maintains data integrity right from the start of the process.
- Run a comprehensive DQ check on the source table: Once the status of the last known data quality issues is checked, a comprehensive data quality check is run on the source table. This ensures that no new issues have emerged since the last check, guaranteeing that the data being processed remains clean and valid. At this stage, the system may check for issues such as incomplete data, duplicates, or incorrect formats. If any severe data quality issues are found, the pipeline can halt, preventing unclean data from being transformed and loaded into the fact table or target table. This ensures that only validated data moves forward in the pipeline.
- Transform and load data into the fact table: After the source table data passes all quality checks, it is transformed and loaded into the fact table. The fact table is a critical component in data warehousing, typically storing numerical or quantitative data that can be analyzed for insights, such as sales figures or transaction amounts. During this transformation, aggregations and calculations may be applied, and further checks are conducted to ensure that these transformations maintain data accuracy. By ensuring the integrity of the transformations, the fact table serves as a reliable source of information for further analysis.
- Run data quality checks at the target table: The final step in the workflow involves running data quality checks at the target table. After the data has been transformed and loaded, the target table represents the final destination, often in a data warehouse, where the data is prepared for downstream use, such as reporting or analytics. Because new pipelines or processes may have contributed data to the same destination, this step ensures that no new issues have been introduced during the data load. If any inconsistencies or problems are detected, the pipeline can either halt or trigger alerts, ensuring that only high-quality data is available for analysis in the target table.
Role of Orchestration Tools
Orchestration tools, such as Apache Airflow, are integral in managing and automating the workflow that connects data pipelines and the data quality platform. These tools schedule and coordinate tasks across the different components, ensuring seamless connectivity and execution. They handle task dependencies, retries, and error management, providing a cohesive framework for integrating data quality checks into the pipeline. By orchestrating the interaction between the data quality platform and the data pipelines, these tools enhance the reliability and efficiency of the entire data process. This integration ensures that data quality checks are consistently applied and that data flows smoothly from source to fact to target table, with minimal manual intervention and maximum data governance.
How DQLabs integrates with data pipeline tools
So how does DQLabs integrate with data pipeline tools? DQLabs offers an array of APIs that is compatible with most orchestrators. Orchestrators from Luigi to Rundeck to Control-M all have the ability to invoke a process via API and wait for a response. Many ETL tools, such as Mulesoft have in-built orchestration as well.
What you are looking to accomplish is the following image:
You will be enhancing your workflow with a few additional API calls to ensure you have data available to process and that the processing is complete and ready for the next step. This is the circuit breaker development method.
Let us walk you through a simplistic real life example:
| Steps | Call | Orchestrator |
| 1 | Call DQLabs to Get a DQ score | Is the DQ Score good? |
| 2 | Execute ETL to move data from stage to Fact | Job Completed |
| 3 | Call DQLabs to Get Fact table score | Is DQ Score good? |
| 4 | Execute ETL to move data from Fact to Report | Job Completed |
| 5 | Get the final score from reporting | Is DQ Score good? |
For this example, we will pick dBT (and yes it can be FiveTran, Talend, Mulesoft and a whole list of others) for your data transformation. Most ETL tools come with a scheduling mechanism, but few have a logic processor that allows you to run external commands. Some may have built testing abilities, but their process is encapsulated as a part of the job. Leveraging an orchestrator to first run a freshness test on the stage environment can be a process cost savings and preventative method from having downstream bad data.
Step 1: Call DQLabs API to get a DQ score and value for a particular asset.
- Step 2: Call DBT has an API Endpoint that can be called to Run a job, Stage to Fact, and you may have to run another API loop to monitor for job completion.
- Step 3: Call DQLabs API to run DQ on a particular asset and wait for completion. Then call to get the DQ score value for that asset, based on your threshold stop or proceed
- Step 4: Call DBT has an API Endpoint that can be called to Run a job, Fact to Reporting, and you may have to run another API loop to monitor for job completion.
- Step 5: Call DQLabs API to run DQ on a particular reporting asset and wait for completion. Then call to get the DQ score value for that asset, based on your threshold stop or proceed.
Conclusion
Integrating data quality checks into pipelines is essential for ensuring reliable and accurate data throughout its lifecycle. By combining DQLabs with orchestration tools such as Apache Airflow and ETL solutions like dbt, organizations can automate quality checks, prevent bad data from moving downstream, and improve operational efficiency. This proactive approach enhances data trust, speeds up issue detection and resolution, and supports data-driven decision-making. Ultimately, integrating data quality within pipelines ensures high-quality data is available for critical business decisions, reducing errors and driving better outcomes.
Experience Augmented Data Quality and Data Observability firsthand. Schedule a personalized demo today.