
Summarize and analyze this article with
Is your organization struggling to manage increasing volumes of data from multiple sources? Are data silos and inconsistent formats slowing down your decision-making? Without a modern data platform, integrating, processing, and analyzing data can become overwhelming—leading to missed insights and operational bottlenecks.
What does it take to build a scalable data platform that meets your organization’s needs? In this blog, we’ll break down the key components, best practices, and steps to design a data platform that empowers smarter, faster decisions.
What is a Data Platform?
A data platform is a collection of key processes and technology components that enable the collection, transformation, sharing, and analysis of data to generate business value. It manages the entire data lifecycle—from ingesting raw data to delivering actionable insights—supporting various business use cases.
An effective data platform handles end-to-end data engineering and management, ensuring data is accessible, reliable, and ready for analysis, empowering organizations to turn data into valuable business products.
With an enterprise-grade data platform, businesses can unify fragmented data sources, eliminating inconsistencies that lead to poor decision-making.
A data platform is a collection of key processes and technology components that enable the collection, transformation, sharing, and analysis of data to generate business value. A good data platform takes care of end-to-end data engineering and management needs of converting raw data into actionable business data products.
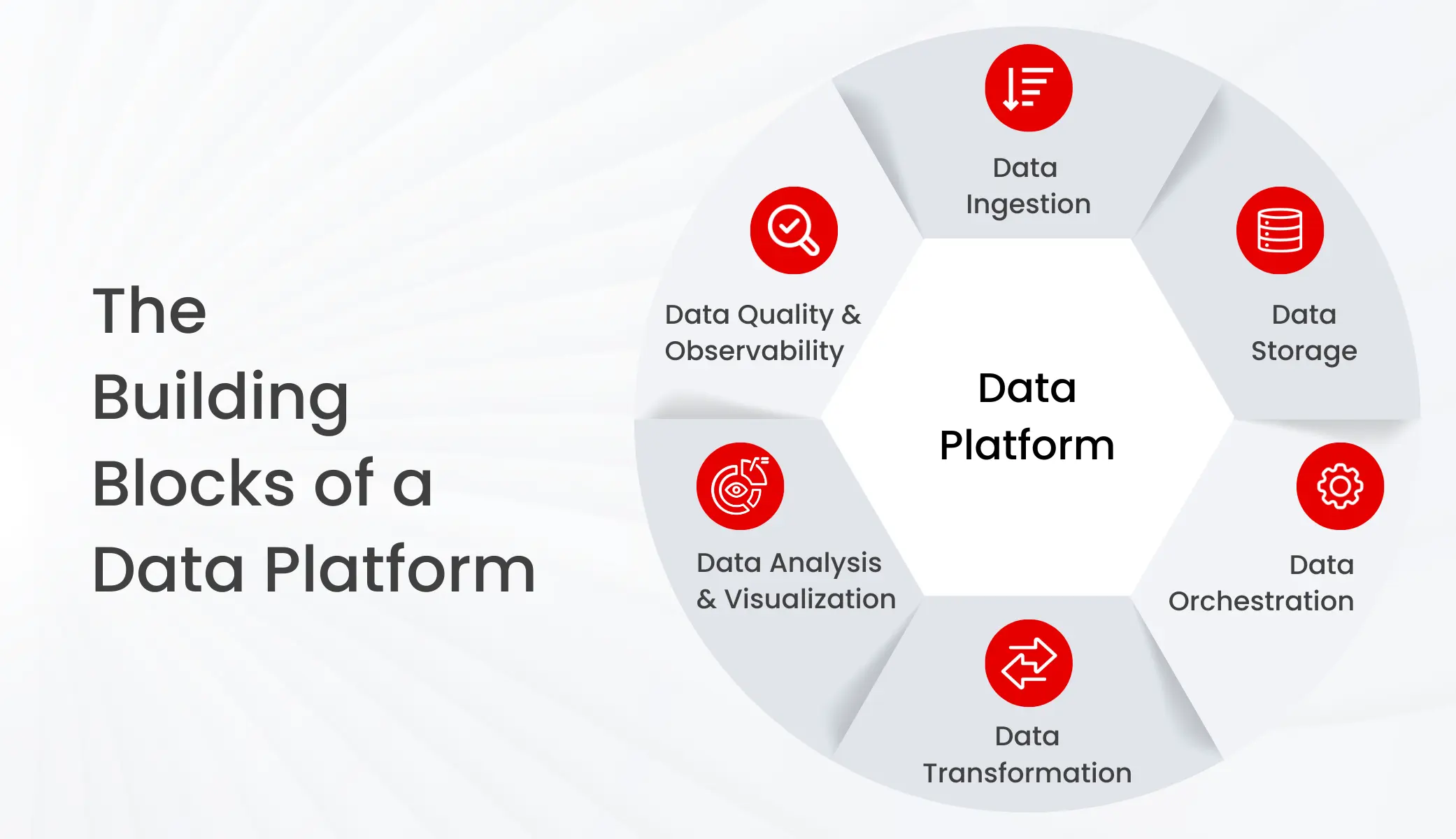
Key Components of a Data Platform
Based on organizational requirements, a data platform’s capabilities might differ. Multinational companies’ data platforms would be significantly different from what startups are using. However, there are certain building blocks of data platforms that should be relevant for organizations of all shapes and forms.
Data Ingestion
The first key component of a data platform is data ingestion. Data ingestion refers to the process of connecting to the data sources and migrating that data to a target destination (data warehouse, data lake etc.) using data pipelines. There are two major kinds of data ingestion processes: batch and near-real-time data ingestion. Batch ingestion is used for a variety of use cases including retail sales analysis, supply chain management, historical data analysis, etc. Whereas, real-time data ingestion is crucial for financial fraud detection, online gaming, trading platforms etc.
A strong data platform enables seamless ingestion from various structured and unstructured data sources, ensuring smooth data integration.
Data Storage
Data resides in the data storage layer after being collected. There are different types of data storage options available for organizations such as – data warehouse, data lake, and data lakehouse. Organizations can choose specific data storage as per their use cases’ demand. A Data warehouse is ideal when you want your data to be in a structured format for fast querying and analysis. Data lake provides a low-cost data storage option for all data types (structured, semi-structured, and unstructured). A data lakehouse architecture combines the capabilities of a data warehouse and data lake and provides the capability to store data in its raw form with efficient and fast data queries.
Choosing the right storage option is essential for optimizing data retrieval and processing within a data platform.
Data Orchestration
This layer provides end-to-end management and scheduling of all data workflows. In the current data landscape, organizations deal with large volumes of data spread across multiple sources. This makes the data pipelines complex and interdependent, which makes manual scheduling and management an impossible task. Data orchestration provides an automated way to streamline the management of data pipelines to ensure timely data delivery.
A modern data platform incorporates automated orchestration to enhance pipeline efficiency and reduce manual intervention.
Data Transformation
Data in the storage layer is not yet consumption-ready for data and analytics initiatives. It needs to go through certain transformation steps before it’s ready to be consumed by downstream users. In data transformation, raw data goes through a series of cleansing (for example, missing value treatment), data validation (including outlier treatment), and restructuring (like merging datasets) steps.
With an advanced data platform, organizations can automate complex data transformation workflows, ensuring clean and structured data.
Data Analysis and Visualization
Data analysis is a data consumption layer with different tools such as BI reports and dashboards, machine learning-enabled tools, and self-service business user tools (say, a pricing tool for a sales team) – all of which consume data from the consumption layer for its intended business purpose.
An effective data platform ensures that data consumers, from analysts to business teams, can access real-time insights effortlessly.
Data Quality and Observability
The best of an organization’s data initiatives are likely to fail if data quality isn’t good. In today’s complex data environment, it has become very difficult to detect and troubleshoot data quality issues. Organizations need modern data quality tools that provide data monitoring, troubleshooting, and automated business quality checks to ensure consistent delivery of high-quality data to end users. Good data quality tools enable organizations to proactively monitor and analyze their data pipelines, model performance, and potential biases in real time and reduce the cost implications of poor data quality.
A modern data platform integrates data quality and observability features, proactively identifying and resolving inconsistencies before they impact decision-making.
Key Features of a Data Platform
Data Ingestion Tools
Organizations need data ingestion tools that provide out-of-the-box connectivity to various popular structured, unstructured, and semi-structured data sources. Ideally, organizations should have a combination of batch and real-time data ingestion tools. AWS Glue, Stitch, and Fivetran are some of the popular data ingestion tools.
Data Storage Layer
Based on the specific use case requirements organizations can select data lake, data warehouse, or data lakehouse options. AWS, Microsoft Azure, and GCP provide low-cost data lake options whereas Snowflake, Amazon Redshift, and Google Big Query are popular choices for cloud data warehouses. Data lakehouse is pioneered by Databricks and Databricks Delta Lake is one of the most popular solutions. Other industry leaders like Snowflake and Microsoft also provide data lakehouse solutions and offerings.
Data Orchestration
Data orchestration tools automate the process of managing and scheduling data pipelines to increase efficiency and improve consistent data delivery. Some popular data orchestration tools are Apache Airflow (open source), Luigi, Dagster, and Prefect. Apache Airflow is one of the most popular orchestration engines due to its flexibility, scalability, and community support. Dagster provides unified data pipeline programming whereas Luigi provides simplicity and ease of use of pipeline orchestration.
Data Transformation
Data transformation tools convert data into analytics-ready datasets format. Dbt (data build tool) is one of the most popular open-source data transformation tools. Other popular players in this domain include – Datameer, Hevo Data, and Matillion. Datameer excels in integrating seamlessly with the Hadoop ecosystem, leveraging its strengths in processing large-scale data on distributed systems.
Data Visualization and Analysis
Data analysis and visualization tools provide an interface to explore and visualize data. Some of the popular data visualization tools include Power BI, Looker, and Tableau. Tableau has been used by companies for many years due to its ease of use, powerful analytics capabilities, scalability, enterprise features, and continuous innovation in the data visualization space. On the other hand, enterprises using the Microsoft Suite may prefer Power BI due to easy compatibility with MS Excel and other Microsoft products.
Data Quality and Observability
Data quality is the heart of an organization’s data-driven initiatives. Poor data quality can derail progress and prevent organizations from being truly data-driven. To ensure robust data quality management, organizations need tools that enable data quality and observability through a single platform. DQlabs’ Modern Data Quality platform provides role-based and relevant data and business quality checks that fuel better decision-making and ensure effective business outcomes.
Traditional Data Platform vs. Modern Data Platform
As data needs evolve, modern data platforms offer more flexibility, scalability, and real-time insights compared to traditional platforms. While traditional data platforms focus on structured data and on-premise systems, modern data platforms are cloud-native, handling diverse data formats with advanced automation.
| Feature | Traditional Data Platform | Modern Data Platform |
| Infrastructure | On-premise, fixed capacity | Cloud-native, scalable on demand |
| Data Types | Structured Data Only | Structured, semi-structured, unstructured |
| Data Processing | Batch processing | Real-time and batch processing |
| Scalability | Limited and expensive | Flexible and cost-efficient |
| Automation | Manual data workflows | Automated pipelines with orchestration |
| Data Quality Management | Reactive issue handling | Proactive monitoring and observability |
| User Access | IT-centric, limited self-service | Self-service for business users |
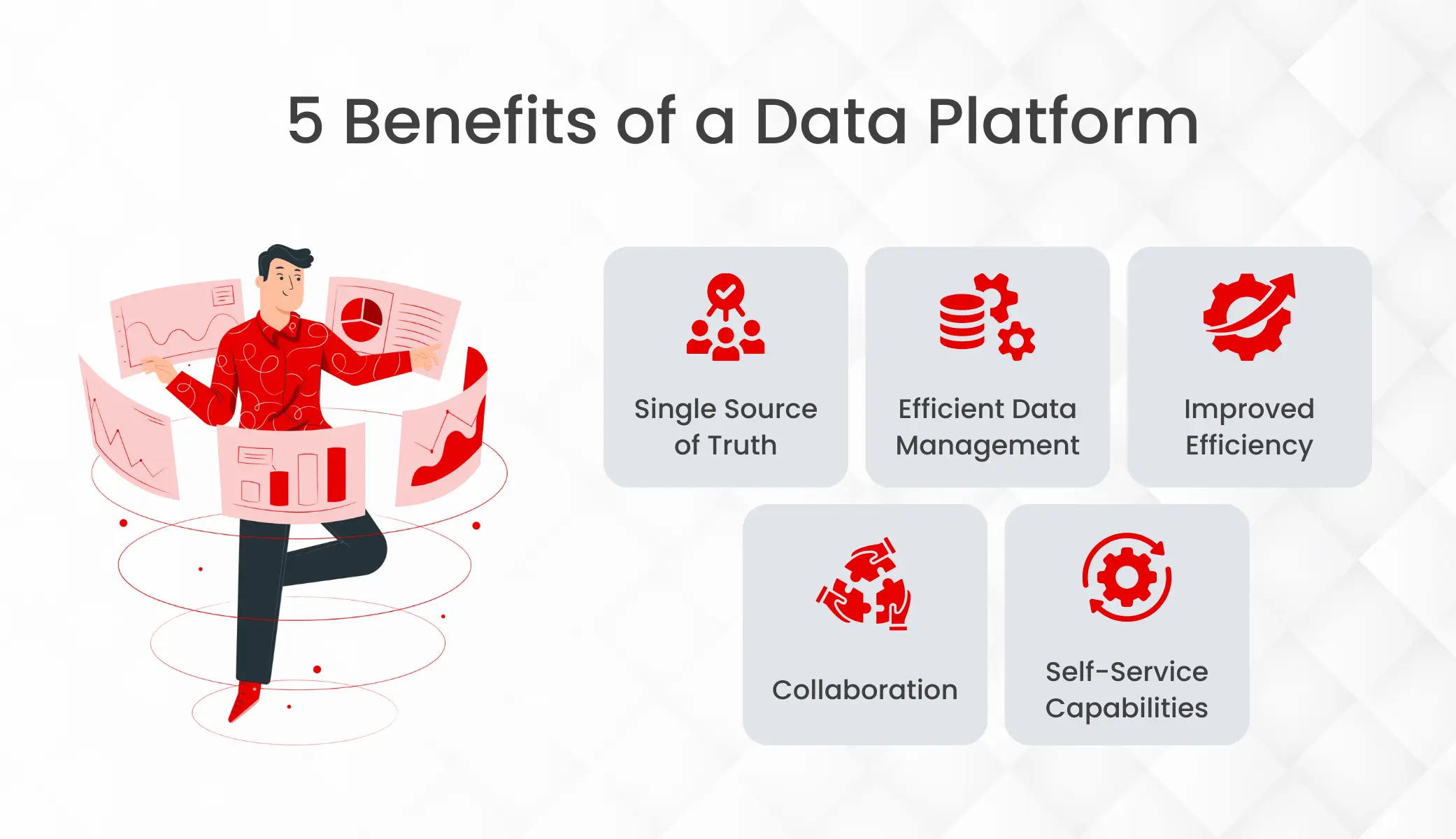
Benefits of a data platform
Single source of truth
A data platform is the first step for an organization to become data-driven. By eliminating data silos in the organization and integrating all data sources effectively, a data platform provides a single source of truth for data.
Efficient data management
A data platform enables organizations to manage their ever-increasing data landscape. By providing end-to-end data management solutions, data platforms enable data integrity, consistency, and quality across the organization.
Improved efficiency
By leveraging automation and AI-driven workflows, a data platform reduces manual data handling, improving efficiency across both data teams and business units. The right data platform enables seamless data ingestion, transformation, and analysis.
Collaboration
A good data platform provides a mechanism for different data and business personas to interact and work together on data initiatives. With built-in sharing, lineage tracking, and access controls, a data platform ensures that data is both accessible and governed properly. This promotes a culture of data sharing, collaboration, and data-driven decision-making across the organization.
Self-service capabilities
A modern data platform empowers business users by providing self-service access to data. By reducing dependency on IT and data engineering teams, a data platform accelerates insight generation, making organizations more agile and data-driven.
What to Consider Before You Start Building Your Data Platform
Before building a data platform, organizations must evaluate their unique data needs and infrastructure. This involves understanding the nature of their data sources, defining user personas, and ensuring scalability to support future growth. A well-designed data platform should also align with security and compliance policies while embracing modern architectures like multi-cloud and hybrid environments.
Organizations need to consider some key questions before starting their data platform journey.
Data sources
What are the types of data sources you own? Are they structured, semi-structured, or unstructured? How many different data sources are you using? How will your data platform connect and integrate these sources? These questions, and more, will help organizations to select and then shortlist data ingestion vendors, based on their relevant capabilities.
The answers will determine which data ingestion solutions best fit your data platform strategy.
Distributed architecture
Organizations should consider adopting a multi-cloud or hybrid-cloud architecture for their data platform. A distributed data platform prevents vendor lock-in, ensures compliance, and optimizes costs by leveraging different cloud providers’ strengths.
A well-architected distributed data platform enhances flexibility, allowing organizations to choose the best cloud services for different workloads while ensuring seamless data integration and governance across environments.
Persona needs
Who are the primary consumers of your enterprise data platform? Is it Max, who works in the data science team, or is it Mark, the marketing manager? Do you need a data platform that serves only technical teams (data scientists, engineers) or one that also caters to business users?
A data platform designed for technical users might focus more on automation and scalability, while a business-user-friendly data platform should emphasize self-service and ease of access. With more & more focus on data democratization, there might be certain organizations that need a data platform just for their technical personas like data scientists and data analysts. For this, they might not invest as much in self-service data management or collaboration capabilities.
Other organizations may want to empower their business and non-technical personas, for which they would create a data platform that enables collaboration and self-service data management practices. Here, the focus would be on building a culture, in addition to data access & management.
Security and compliance
Security is a critical consideration for any data platform. Data security and compliance policies might differ from organization to organization. Based on one’s own needs, organization-level policies should be established for data security and compliance.
Organizations should also ensure that their data platform adheres to industry regulations like GDPR, HIPAA, or CCPA, minimizing legal risks and protecting user privacy. Automated compliance monitoring within a data platform can help organizations detect and address potential security vulnerabilities before they become threats.
Scalability
A data platform should be built to scale as data volumes grow. Organizations must anticipate their future data needs and design a data platform that can accommodate increasing complexity, users, and workloads.
By addressing these factors, organizations can create a data platform that supports both immediate and long-term data goals.
The above questions would help organizations to introspect, reflect on their data needs, and accordingly choose & build a robust data platform.
Conclusion
Establishing a robust data platform is not just a technological effort but a strategic initiative for any organization aiming to enable a data-driven culture.
A well-executed data platform empowers businesses to make informed decisions, improve operational efficiency, and accelerate innovation. It serves as one of the key levers for achieving data-driven success and staying competitive in today’s dynamic business environment.
By addressing fundamental questions such as the number and diversity of your data sources, which user personas your data platform is catering to, what security and compliance measures need to be in place, and by planning for scalability, organizations can lay a strong foundation for their data initiatives.
FAQs
What Is a Modern Data Platform?
A modern data platform is a cloud-native system that integrates, processes, and analyzes structured, semi-structured, and unstructured data. Unlike traditional data platforms, which are on-premise and limited to batch processing, modern data platforms offer scalability, real-time data handling, and advanced automation. They also enable proactive data quality monitoring and provide self-service capabilities for business users, ensuring faster, data-driven decision-making.
What Is a Good Data Platform?
A good data platform efficiently manages the entire data lifecycle—from data ingestion and storage to transformation and analysis—while ensuring data quality and observability. It should:
- Support batch and real-time data ingestion.
- Offer flexible storage options like data lakes, warehouses, or lakehouses.
- Automate data workflows using orchestration tools.
- Ensure data quality with proactive monitoring and troubleshooting.
- Provide self-service capabilities for business users to access and explore data.
- Be scalable to accommodate growing data volumes and diverse user needs.
Why Do I Need a Modern Data Platform?
A modern data platform is essential to manage the growing complexity and volume of data. It helps organizations:
- Eliminate data silos by integrating data from multiple sources.
- Ensure consistent, high-quality data for better decision-making.
- Automate data workflows to improve operational efficiency.
- Support real-time insights for critical use cases like fraud detection.
- Empower both technical and business users through self-service access.
- Scale with increasing data demands while maintaining security and compliance.
How to Build a Modern Data Platform?
To build a modern data platform, organizations should follow these steps:
- Understand Data Sources – Identify structured, semi-structured, and unstructured data.
- Choose a Distributed Architecture – Multi-cloud and hybrid-cloud approaches provide flexibility.
- Define User Personas – Ensure the data platform meets the needs of both technical and business users.
- Implement Key Components
- Data Ingestion – Support batch and real-time pipelines.
- Storage Layer – Choose data lakes, warehouses, or lakehouses.
- Orchestration – Automate pipelines using orchestration tools.
- Transformation – Make data analytics-ready.
- Analysis & Visualization – Provide access to BI tools.
- Data Quality & Observability – Maintain data integrity with platforms like DQLabs.
- Ensure Security & Compliance – Align with internal and regulatory policies.
- Plan for Scalability – Design a data platform that can grow with your business.
By following these steps, organizations can build an enterprise data platform that is resilient, scalable, and future-ready.