Data Quality Automation
Data Quality Automation https://www.dqlabs.ai/wp-content/uploads/2024/06/17-1024x575.webp 1024 575 DQLabs https://www.dqlabs.ai/wp-content/uploads/2024/06/17-1024x575.webpData is an integral part of today’s modern businesses. When managed correctly as part of an effective data quality management (DQM) strategy, it can propel organizations to exceptional success. Conversely, if left unattended without proper governance, data can lead to significant setbacks.
The 2023 Gartner Chief Data and Analytics Officer Agenda Survey highlights that a huge spending goes towards data management, data governance and advanced analytics to maintain high data quality across different sources and landscapes.
Ensuring high-quality data requires the enforcement of strong DQM policies and procedures. In the complex landscape of data fabrics and meshes, this can get overwhelming. Especially when organizations still rely on traditional and non-scalable techniques.
Maintaining accurate data is further complicated by data management architectures that must handle an increasing volume of data while meeting strict security, privacy, and regulatory compliance requirements. As a result, reducing manual effort in data quality processes is becoming more essential.
This raises the question: what steps should be taken to achieve better data quality company-wide?
But before diving into that, let’s see why traditional data quality is not scalable and what are the benefits of automating your data quality processes.
Drawbacks of Traditional Data Quality
More Manual Labour
In the early days of data quality processes, companies often used a mix of SQL rules and spreadsheets for documentation—a practice still common among Fortune 500 firms. These tables list data sources, attributes, and various standard data quality rules, which SQL developers then implement directly in the database.
This method requires creating unique data quality rules for each data source or asset. When business definitions or data structures change, each rule must be updated individually, leading to inefficiency and increased workload. This highlights the need for scalable, automated solutions. A frustrated data engineer says,
Those code-heavy systems are a nightmare to scale! Every new data source feels like needing more hands on deck to write even more code. We need a more flexible way to handle this!
Growing Complexity
The characteristics of big data are encapsulated in the 4Vs: Volume, Velocity, Variety, and Value.
Due to these 4V characteristics, enterprises face a pressing challenge when using and processing big data: extracting high-quality, real-time data from vast, diverse, and complex datasets.
The multitude of data sources introduces a wide array of data types and intricate data structures, amplifying the complexity of data integration. With enormous data volumes, assessing data quality promptly becomes challenging too. Moreover, rapid data changes shrink the window for data to remain timely, demanding advanced processing technologies to meet these heightened requirements.
Financial Implications
When scaling operations, relying predominantly on manual data quality processes can have a substantial financial impact on the overall budget designated for Data Quality Approaches. Costs escalate due to several factors like the initial implementation of rules, adjustments to evolving business requirements, schema modifications within systems, and the integration of new data sources.
These challenges emphasize the importance of automating data quality processes to mitigate financial strain and operational overhead. Automation not only enhances efficiency but also reduces costs associated with manual interventions, ensuring a more robust and sustainable approach to managing data quality at scale.
Benefits of Automating Data Quality Processes
- Improved Accuracy and Reliability: Automated cleansing and validation eliminate errors and inconsistencies, ensuring trustworthy data for confident decision-making.
- Enhanced Decision-Making: Clean, consistent data fuels insightful analysis, leading to better strategic planning and business growth.
- Increased Efficiency and Cost Savings: Automation streamlines data management, freeing up resources and reducing costs associated with manual efforts and errors.
- Mitigated Risks: Proactive identification of data issues minimizes the risk of bad decisions, compliance violations, and reputational damage.
Automation Technologies Used in DQ Workflows
To automate data quality, we need to:
- Connect data sources and automatically identify key domains (names, addresses, etc.) using an augmented data catalog.
- Experts set data quality rules centrally for validation and standardization across all sources.
- Deploy profiling and AI to automate data mapping and rule application. New data sources inherit existing rules for seamless integration.
But, addressing the resource challenges posed by expanding data volumes and leveraging subject matter expertise, data quality software is undergoing a significant transformation. This evolution involves enhancing user interaction experiences and adopting innovative technologies. Below are the five pivotal technologies driving these advancements:
Metadata
Talking to business users is the key for successfully implementing data quality programs. We need to understand the data (datasets, elements, definitions), how it flows (processes), and who’s responsible (stewardship).
Traditionally, this info lived in spreadsheets.
Now, it is captured as metadata in data catalog and governance software. Consequently, data quality solutions are now integrated with data catalog, data governance, and data quality capabilities.
Discovered metadata automates repetitive data quality processes by linking quality rules to data assets, ensuring consistent application. Metadata also automates remediation workflows and sets accessibility levels for sensitive data based on user roles.
How does metadata help you?
- Data connects, platform profiles, classifies & discovers – all data assessed based on updated metadata.
- Defines rules centrally – logic only, not source connection – reuses across different data sources.
- Less manual configuration & rework, fewer people needed for data quality.
- Handles terabytes to exabytes, adapts to new data sources & processing demands.
- Analyzes data at any level, anywhere – batch, real-time, or streaming modes.
Artificial Intelligence (AI) & Machine Learning (ML)
In automating data quality, artificial intelligence (AI) and machine learning (ML) play a major role. Supervised learning with pre-trained models helps identify entities in unstructured data, reducing manual effort. Semi-supervised and active learning use user feedback to refine models for even better automation. Unsupervised methods find patterns and outliers, aiding data profiling and rule creation. Generative AI, particularly large language models, are integrated into data quality solutions to create complex data quality rules. These AI-powered applications leverage metadata, knowledge graphs, and user interactions to automate tasks, significantly improving data quality and efficiency.
Read more: How AI and ML are transforming data quality management?
Knowledge Graphs
Understanding data quality requires answering questions about data availability, access, usage, values, responsibilities, relevance, origin, standards, correction processes, and user trust. Knowledge graphs with metadata, is key to automating this process. As they link data elements, providing context and enabling automated data profiling. Data governance tools leverage this to create data quality profiles with applied rules, saving analysts time. Generative AI takes this a notch further by integrating data quality checks directly into analytical workflows, so users can seamlessly query, identify and address data issues.

Natural Language Processing (NLP) & Large Language Models (LLMs)
NLP and LLMs significantly help in automating data quality by enhancing data understanding and processing. NLP excels at parsing and interpreting human language, enabling the identification and classification of data attributes, such as names and addresses, from unstructured text. LLMs build on this by providing more sophisticated analysis and generating complex data quality rules.
These technologies facilitate the creation of data quality rules by translating business requirements into executable code. They also help detect anomalies, standardize data formats, and automate data profiling, reducing the need for manual intervention and improving overall data accuracy and consistency. Many data quality solutions are coming up with their proprietary LLM interface built within their platforms to improve their user experience.
Check out Gartner’s assessment of Augmented Data Quality Solutions based on the above four key features here → Magic Quadrant for Augmented Data Quality Solutions
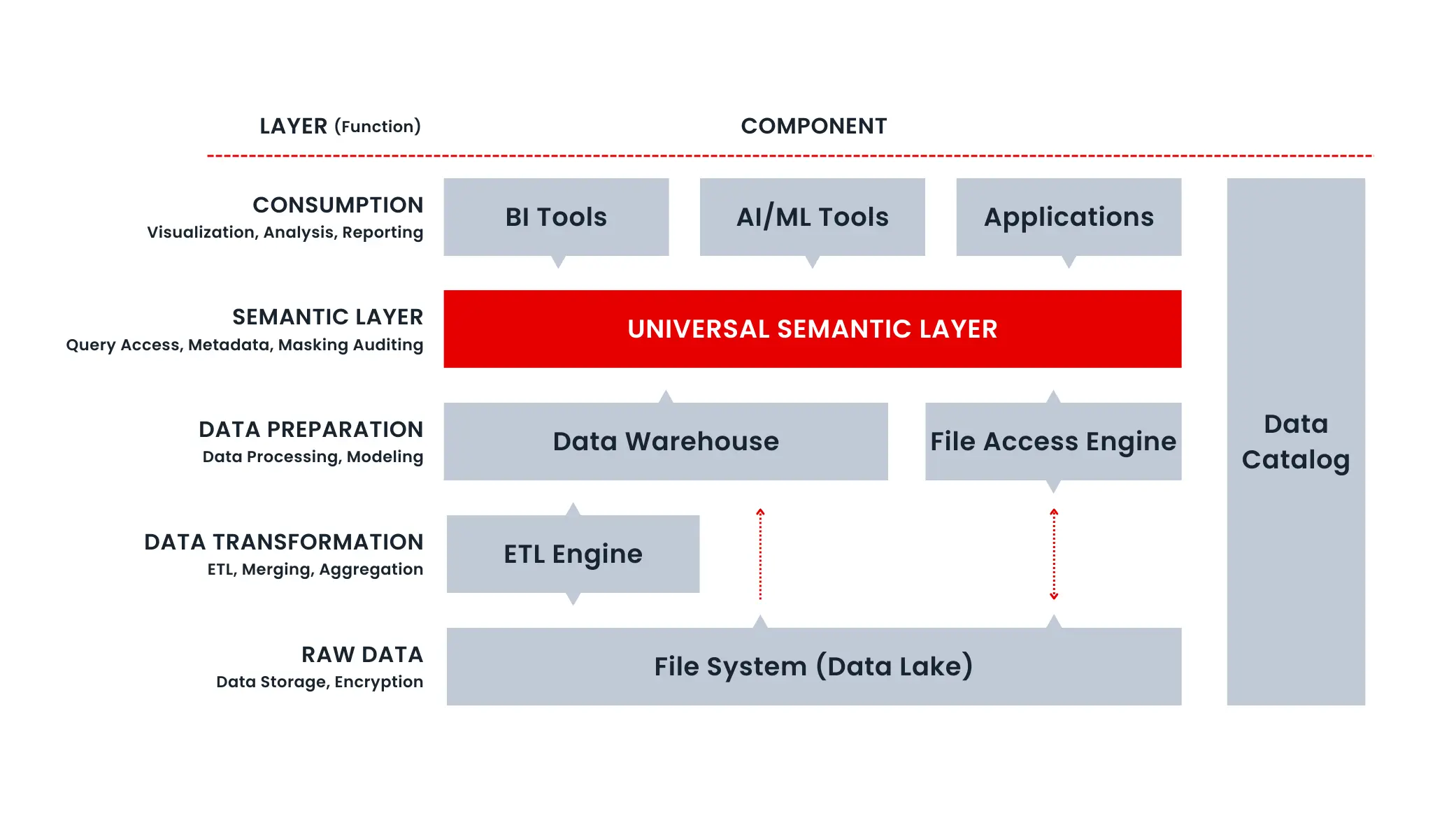
Semantic Layer
As mentioned earlier, data complexity is exploding with big data, cloud warehouses, and self-service analytics. Businesses crave faster, better insights, but many have deployed various data and analytics solutions across different platforms, leading to data silos. Fragmented data platforms make it tough to ensure clean, consistent data for everyone.
The semantic layer serves as middleware, connecting data sources and analytics platforms through virtualized connectivity and modeling. By filtering all necessary data through the semantic layer, it ensures data scientists and business users view consistent data, making it actionable and enhancing business insights.
AI-powered Enhancements in DQ
Data quality solutions are packed with features that are undergoing significant automation. This means you can analyze and improve your data faster and with greater accuracy compared to traditional methods. Some of the ways in which AI could strengthen your data quality efforts are listed below:
- Identifies potential issues: Machine learning scans data for unusual patterns, like changes in data types or missing values. Users don’t need to set rules, AI learns what’s normal and flags deviations.
- Prioritizes high-impact issues: AI learns from user behavior to prioritize alerts. Issues in frequently used or high-value data get addressed first. Repeatedly ignored problems get deprioritized.
- Assists with corrections: AI analyzes how humans correct data and suggests fixes. This helps with recurring issues that require manual review but can be addressed with learned patterns.
- Resolving duplicates: AI analyzes data to suggest the best combinations of fields (name, address, phone) for finding duplicates, saving users time on manual configuration.
- Matching process: Users review a small sample of AI-suggested matches, and AI learns from their decisions. This allows AI to automatically resolve many uncertain matches, significantly reducing manual work.
- Parsing with Named Entity Recognition (NER): NER uses machine learning to extract entities from unstructured text, aiding in data quality tasks like parsing addresses and detecting sensitive information. These techniques can identify and extract various entities from text, like names, locations, or dates.
- Unstructured text classification: This uses machine learning to categorize text into predefined classes. Examples include – routing customer support requests to the right team, recognizing different languages in text data, and grouping similar product descriptions together.
- Data standardization: AI clusters similar data attributes and suggests standard values, streamlining standardization. LLMs assist with manual remediation by suggesting correct standards and formats for data attributes.
- Top-down data profiling: AI helps curate data attributes and link them to business terms and quality rules. It learns patterns and automatically assigns these rules, accelerating discovery and improving data quality. This is ideal for data governance and analytics with high data volumes.
- Bottom-up data profiling: Unsupervised learning analyzes data patterns and identifies anomalies or inconsistencies. AI helps spot these issues across massive datasets, making data quality checks more efficient, especially for data warehouses and data lakes with incremental data loads.
- Rule deployment: Traditionally, business and technical collaboration was necessary to define and implement rules, posing challenges due to evolving business practices and the complexity of rule deployment. To streamline this, AI empowers business users with self-service capabilities through two methods: NLP/LLM-based rule generation and automated rule inference.
- Rule generation & inference: NLP converts business descriptions into executable code, automating rule creation without technical coding. LLMs enhance this by handling complex datasets and relationships between attributes. Alternatively, automated rule inference uses AI to infer patterns from data, suggesting rules for SMEs to curate and deploy. These AI-driven approaches accelerate rule development, reduce dependency on technical resources, and enhance data quality monitoring across diverse datasets and business environments.
Try DQLabs – a Modern Data Quality Platform with AI, ML, NLP and other advanced analytics capabilities. Talk to us to know more!
Considerations When Automating Your Data Quality Processes
To ensure successful data quality automation, technical professionals should consider these key points:
MDM & Governance Integration
Choose solutions that integrate data governance and catalog capabilities. These solutions should seamlessly classify and qualify large datasets, for data consumer usability. Look for metadata-driven approaches that connect governance policies with data quality rules, especially in environments like MDM where governance is a success factor
Opt for tools that:
- Integrate tightly with data catalog, governance, and data quality functionalities.
- Automatically suggest data quality rules based on metadata analysis.
- Generate quality metrics automatically within the governance framework.
- Support high business self-service, reducing dependency on technical setup through user-friendly methods or NLP augmentation.
AI-Enabled Data Quality Tools
Modern AI-driven data quality tools offer agile solutions to complex data challenges. They autonomously learn from data, infer rules, and detect anomalies, surpassing traditional methods. Handling vast datasets and numerous attributes, these tools uncover thousands of rules that SMEs and manual processes can’t. They adapt to evolving business practices and data patterns, proactively preventing data quality issues.
Look for data quality tools with:
- Automated profiling
- Anomaly detection
- Rule inference
- Explainable AI features
- Minimal manual analysis
- Fast issue discovery
Focus on Root Cause & Data Fixes
While AI excels at finding data quality problems, it can overwhelm us with too many issues to fix. This means we need to shift resources from building data quality checks to actually resolving the data issues unearthed by AI. Technical teams should prioritize building processes to improve data quality and address the growing backlog of identified problems.
Transparency for Trust
Quality data builds trust. Automated processes can also make mistakes, eroding trust in both data and automation itself. To succeed, data quality automation needs to be explainable: technical teams must log and explain why/how data quality issues arise. This builds trust in automation.
Conclusion
Automating data quality processes enhances accuracy and efficiency, empowering better decision-making and cost savings. Yet, ensuring reliability and transparency is crucial. Integrating metadata, AI, and NLP furthers automated governance and rule generation, while focusing on root causes ensures effective issue resolution. Maintaining transparency in AI-driven automation builds trust, which is crucial for sustained data quality improvements and operational success.